Lambros D. Callimahos
from Military Cryptanalytics Pt. 3

NATIONAL SECURITY AGENCY FORT GEORGE G. MEADE, MARYLAND 20755-6000
FOIA Case: 68177B 9 December 2020
This responds to your Freedom of Information Act (FOIA) request of 7 July 2012 for "a copy of Military Cryptanalytics, Part III, by Lambros D. Callamahos. Please review the sections marked as classified for possible declassification and release." A copy of your request is enclosed. Your request has been processed under the FOIA and the document you requested is on the enclosed CD. Certain information, however, has been deleted from the enclosure.
Some of the withheld information has been found to be currently and properly classified in accordance with Executive Order 13526. The information meets the criteria for classification as set forth in Subparagraph (c) of Section 1.4 and remains classified SECRET as provided in Section 1.2 of Executive Order 13526. The information is classified because its disclosure could reasonably be expected to cause serious damage to the national security. Because the information is currently and properly classified, it is exempt from disclosure pursuant to the first exemption of the FOIA (5 U.S.C. Section 552(b)(1)). The information is exempt from automatic declassification in accordance with Section 3.3(b)(1) of E.O. 13526.
In addition, this Agency is authorized by various statutes to protect certain information concerning its activities. We have determined that such information exists in this document. Accordingly, those portions are exempt from disclosure pursuant to the third exemption of the FOIA, which provides for the withholding of information specifically protected from disclosure by statute. The specific statutes applicable in this case are Title 18 U.S. Code 798; Title 50 U.S. Code 3024(i); and Section 6, Public Law 86-36 (50 U.S. Code 3605).
Since these deletions may be construed as a partial denial of your request, you are hereby advised of this Agency's appeal procedures.
FOIA Case: 68177B
You may appeal this decision. If you decide to appeal, you should do so in the manner outlined below. NSA will endeavor to respond within 20 working days of receiving any appeal, absent any unusual circumstances.
• The appeal must be sent via U.S. postal mail, fax, or electronic delivery (e-mail) and addressed to:
NSA FOIA/PA Appeal Authority (P132) National Security Agency 9800 Savage Road STE 6932 Fort George G. Meade, MD 20755-6932
The facsimile number is 443-479-3612. The appropriate email address to submit an appeal is FOIARSC@nsa.gov.
- It must be postmarked or delivered electronically no later than 90 calendar days from the date of this letter. Decisions appealed after 90 days will not be addressed.
- Please include the case number provided above.
- Please describe with sufficient detail why you believe the denial of requested information was unwarranted.
You may also contact our FOIA Public Liaison at foialo@nsa.gov for any further assistance and to discuss any aspect of your request. Additionally, you may contact the Office of Government Information Services (OGIS) at the National Archives and Records Administration to inquire about the FOIA mediation services they offer. The contact information for OGIS is as follows:
Office of Government Information Services National Archives and Records Administration 8601 Adelphi Rd. - OGIS College Park, MD 20740 ogis@nara.gov 877-684-6448 (Fax) 202-741-5769
Sincerely,
RONALD MAPP Chief, FOIA/PA Office NSA Initial Denial Authority
Encls: a/s
SECRET
NATIONAL SECURITY AGENCY
MILITARY CRYPTANALYTICS Part III
By LAMBROS D. CALLIMAHOS
October 1977
Classified by DIRNSA/CHCSS (NSA/CSSM 123-2)
Exempt from GDS, EO 11652, Cat 2
Declassify Upon Notification by the Originator
National Security Agency Fost George G. Meade, Maryland
SECRET
SECRET
f
I 'L, NATIONAL SECURITY AGENCY
MILITARY CRYPTANALYTICS Part III
By LAMBROS D. CALLIMAHOS
October 197 7
Classified by DIRNSA/CHCSS (NSA/CSSM 123-2) Exempt from GOS, EO 11652, Cat 2 Declassify Upon Notification by the Originator
National Security Agency Fort George G. Meade, Maryland
Give me an ounce of civet, good apothecary, to sweeten my imagination.
-Shakespeare. (King Lear, Act IV, Sc. 6) r
Preface
I wish to acknowledge my indebtedness to William F. Friedman in drawing upon portions of his early work, "Military Cryptanalysis, Part III," for much of the material treated in Chapters I-V. Chapters IV-XI are revisions of seven of my monographs in the NSA Technical Literature Series, viz.: Monograph No. 19, "The Cryptanalysis of Ciphertext and Plain text Autokey Systems"; Monograph No. 20, "The Analysis of Systems Employing Long or Continuous Keys"; Monograph No. 21, "The Analysis of Cylindrical Cipher Devices and Strip Cipher Systems"; Monograph No. 22, "The Analysis of Systems Employing Geared Disk Cryptomechanisms"; Monograph ~ o. 23, "Fundamentals of Key Analysis"; Monograph No. 15, "An Introduction to Teleprinter Key Analysis"; and Monograph No. 18, "Ars Conjectandi: The Fundamentals of Cryptodiagnosis.''
I also wish to acknowledge my indebtedness to Francis T. Leahy for keeping me out of statistical mischief, and to Bruce W. Fletcher for his expert assistance in the final proofreading, and for checking the cryptograms and the various diagrams.
-L.D.C.
TABLE OF CONTENTS
(b) (3) -18 USC 798 (b) (3) -50 USC 3024(i) (b) (3) -P.L. 86-36
(b)(1)
MILITARY CRYPTANALYTICS, PART III
Aperiodic Substitution Systems

SECRET
| Chapte | er | Page |
|---|---|---|
| VII. | Cylindrical cipher devices and strip cipher systems | 151 |
| 45. General. 46. Reconstruction of unknown cipher alphabets. 47. Analysis of cryptograms involving known alphabets but with unknown keys. 48. Further remarks. | ||
| VIII. | Systems employing geared disk cryptomechanisms | 173 |
| ı | 49. Introduction. 50. The Wheatstone cipher device. 51. Analysis of the Wheatstone cipher device. 52. The Kryha cipher machine. 53. Analysis of the original Kryha machine. | |
| IX. | Fundamentals of key analysis. | 227 |
| 56. Convenient sources of key. 57. Manual key generation methods. 58. Mechanical and electronic key generators. 59. General analytic approaches. 60. Analysis of key in a double transposition cipher. 62. Concluding remarks. | ļ | |
| X. | Teleprinter key analysis | 26 3 |
| ſ | 63. General. 64. Teleprinter key generation methods. 65. Analysis of combination streams. | : ] |
| L | ‡ | |
| XI. | Principles of cryptodiagnosis | 3 2 3 |
| XII. | 71. General. 72. The basic steps in diagnosis. 73. The diagnostician and his attributes. 74. Embarking on the unknown cryptosystem. 75. Preliminary actions in attacking the unknown cryptosystem. 76. First step: manipulating the data. 77. Second step: recognizing the phenomena. 78. Third step: interpreting the phenomena. 79. Post mortem. Concluding remarks | • |
| 81. Special cases of aperiodic encipherment. 82. Analysis and solution of a first case. 83. Analysis and solution of a second case. 84. Final remarks. | • | |
| APPI | ENDICES | • |
| 1. 2. 3. 4. 5. |
De Profundis; or the ABC of Depth Reading Synoptic Tables, Cipher Device M-94 Tables of the Poisson distribution Table of the Binomial distribution for p=1/10 Plaintext and random material for sampling purposes Basic letter frequency data, 24 foreign languages Problems—Military Cryptanalytics, Part III | 437 447 463 537 553 561 611 653 |
| (b) (1) (b) (3) -18 USO (b) (3) -50 USO (b) (3) -P.L. 8 |
C 3024(i) |
(b) (1) (b) (3)-18 USC 798 (b) (3)-50 USC 3024(i) (b) (3)-P.L. 86-36
CHAPTER I
INTRODUCTION
| • | Paragraph | |
|---|---|---|
| Preliminary remarks | 1 | |
| General remarks on cryptographic periodicity | • | 2 |
| Effects of varying the length of plaintext groupings | ||
| Primary and secondary periods; resultant periods | ||
| Cryptographic principles of aperiodic systems | 5 | |
- Preliminary remarks.—a. This text constitutes the third in the series of six basic texts on the science of cryptanalytics. The first two texts together have covered most of the necessary fundamentals of cryptanalytics; this and the remaining three texts will be devoted to more specialized and more advanced aspects of the science.
- b. It is assumed that the cryptanalyst reader has studied Military Cryptanalytics, Parts I and II, and is familiar with the cryptologic terminology, concepts, principles, and techniques of solution of the various cryptosystems treated in those texts. This general background is a necessary prerequisite to the thorough understanding of the principles expounded in this and the succeeding volumes. Where appropriate, however, reference will be made to particular portions of the first two volumes; the reader would be wise to have these volumes handy when undertaking the study of this present text.
- c. The text immediately preceding this one dealt with various types of periodic polyalphabetic substitution, commonly called repeating-key systems. It was seen in these repeating-key systems how a regularity in the employment of a limited number of alphabets, or even the employment of a complete set of alphabets in succession as in a progressive alphabet system, results in the manifestation of periodicity or cyclic phenomena in the cryptogram, by means of which the latter may be solved. The difficulty of solution is directly correlated with the type and number of cipher alphabets employed in specific examples.
- d. Two procedures might suggest themselves to an enemy cryptographer for consideration if he realizes the foregoing circumstances and he thinks of methods to eliminate the weaknesses inherent in repeating-key ciphers. First, noting that the difficulties in solution increase as the length of the key increases, he might consider employing much longer keys as a means of increasing the security of the messages. Upon second thought, however, if the enemy cyptographer recognizes that, as a general rule, the first step in the solution of these ciphers consists in ascertaining the number of alphabets employed, it might seem to him that the most logical thing to do would be to use a procedure which will avoid periodicity altogether, eliminating the cyclic phenomena that are normally manifested within cryptograms of periodic construction, and thus foil even a first step towards solution. In other words, the cryptographer might progress from the use of rather short repeating keys (of perhaps no more than a dozen letters or so) to the use of key phrases of, let us say, 25-40 letters or thereabouts; subsequently, he might embark upon the use of keying procedures which would have the effect of producing keys of a length approximately equal to that of the average message being enciphered; and finally, he might advance to a stage of keying sophistication wherein the key consists of hundreds or thousands of elements, or even of an infinite number of elements (as, for example, in autokey systems).
- Secret
¹ Before the echoes of the first sentence of this third volume have died down, the distinction between the science of cryptanalytics and the art of cryptanalysis should be re-emphasized. The cryptanalyst pursues studies along general and detailed lines, in order to equip himself technically for the duties of the moment or of the future. This parallels quite closely the technical studies of a violinist, who progresses from elementary exercises to the études of Kreutzer and Rode and finally to the Caprices of Paganini; in the meanwhile, the violinist has also studied various solo works and chamber music as a means of enhancing his comprehension and appreciation of music in general. All that a technical background does for the violinist is to give him the means of artistic expression or synthesis of musical thoughts from the coding of clefs, keys, and notes; all that a technical background does for the cryptanalyst is to give him the means for imaginative expression or synthesis of plaintext meanings from the coding of systems, keys, and characters. See also in this connection footnote 5 on p. 3 of Military Cryptanalytics, Part I.
&EGA&f
- e. At this point in our discussion it would be well to examine two terms defined in the previous volume:
- (1) periodic system. A system in which the enciphering process is repetitive in character and which usually results in the production of cyclic phenomena in the cryptographic text.
- (2) aperiodic system. A system in which the method of keying does not bring about cyclical phenomena in the cryptographic text.
The foregoing are practical definitions-nobody in his right mind (and that of course includes all of our readers) 2 would classify a Hagelin C-38 system 3 as periodic just because it really is periodic with a finite cycle of 26x25x23x2 lxl9xl 7 or 101,405,850; nor would the same right-minded individual quibble with the classification of a S_'l'Stem as aperiodic if the length of the key is only 1000 letters and messages very rarely exceed that length. In brief, what we are in effect saying is that, even if a system embraces in its principle a fixed cycle or period, unless the period is considerably shorter than the messages being enciphered (thus permitting the manifestation of cyclic phenomena), the system may nevertheless for all practical purposes be considered as aperiodic since the solution of a message is not predicated on 'lcriting the cipher text on several superimposed cycles and then solving the cryptographic depth thus produced .
- .f. In this text we shall first examine varieties of aperiodic (as just defined) polyalphabetic substitution systems; then we shall study methods of extending or lengthening short mnemonic keys, followed by systems using lengthy keys ( to include digital and teleprinter systems). Subsequently, we shall study methods of solution of some typical cryptomechanisms and cipher machines, and aperiodic combination systems. The text proper will encl with a discussion of principles of key analysis as applied in manual and machine cryptosystems, followed by an extensive treatment of cryptodiagnosis. The appendices include useful cryptologic and cryptomathematical reference material, concluding with a course of problems designed to insure comprehension of the principles expounded in this volume.
- General remarks on cryptographic periodicity.-a. When we consider the nature of periodicity in polyalphabetic substitution systems, we note that it is composed of two fundamental factors, because there are in reality two elements involved in its production. We have appreciated the fact that periodicity necessitates the use of a keying element employed in a cyclic manner; now we begin to realize that there is also another element involved, viz., that unless the key is applied to constant-length plaintext groupings, no periodicity will be manifested externally in the cipher text, despite the repetitive or cyclic use of a constant-length key. This realization is quickly followed by the idea that possibly all periodicity may be avoided or suppressed by either or both of two ways: (1) by using constant-length keying units to encipher variable-length plaintext groupings, or (2) by using variable-length keying units to encipher constant-length plaintext groupings.
- b. In the usual types of polyalphabetic substitution systems, successive letters of the repeating key are applied to successive letters of the text. vVith respect to the employment of the key, the cryptographic process may be said to be constant or fixed in character. This is true even if a single keying unit serves to encipher two or more letters at a time, provided only the groupings of plaintext letters are constant in length. In all such cases of encipherment by constant-length groupings, the apparent length of the period (as found by applying the factoring process to the cryptograms) is a multiple of the real length and the multiple corresponds to the length of the groupings, i.e., the number of plaintext letters enciphered by the same key letter. It is to be noted, however, that all these cases are still periodic, because both the keying units and the plaintext groupings are constant in length.
- Effects of varying the length of plaintext groupings.-a. Now let us consider the effects of making either one or the other of these two elements variable in length. Suppose that the plaintext groups are made variable in length and that the ke~'ing units are kept constant in length. Then, even though the key may be cyclic and may repeat itself many times in the course of encipherment, external periodicity is suppressed, unless the laic governing the variation in plaint ext groupings is itse(f cyclic, and the length of the message is greater than that of the cycle applicable to tMs variable grouping.
2To scholars of English who experience a quick intakP uf breath at this point, the author hatenH to clarify that the parenthetical phrae is intended to modify only the four immediately preceding words.
3Cf. pp. 4,-,8-464 of 1\Iilitary Cryptanalytics, Part II.
b. As an example illustrating the italicized portion of the preceding sentence, let us suppose the correspondents agree to use reversed standard cipher alphabets with the key word SIGNAL, and that in the encryption the message is divided into groups as shown below:
| S | I | G | N | Α | L | S | I | G | N | Α | L | S | I | G |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 12 | 123 | 1234 | 12345 | 1 | 12 | 123 | 1234 | 12345 | 1 | 12 | 123 | 1234 | 12345 |
| C | OM | MAN | DING | GENER | Α | LF | IRS | TARM | YHASI | S | SU | ED0 | RDER | SEFFE |
| Q _ | UW | UG T | KFAH | UWNWJ | L | HN | ARQ | N GPU | PGNVF | I | TR | OPE | RFER | OCBBC |
| N | A | L | S | I | G | N | Α | L | S | I | G | N | A | L |
| 1 | 12 | 123 | 1234 | 12345 | 1 | 12 | 123 | 1234 | 12345 | 1 | 12 | 123 | 1234 | 12345 |
| C | TI | VET | WENT | YFIRS | T | AT | NOO | NDIR | ECTIN | G | TH | ATT | ELEP | HONES |
| L | HS | QHS | WOFZ | KD ARQ | N | NU | NMM | YIDU | OQZKF | C | NZ | NUU | WPWL | EXYHT |
| s | I | G | N | A | L | S | I | |||||||
| 1 | 12 | 123 | 1234 | 12345 | 1 | 12 | 123 | |||||||
| C | OM | MAS | WITC | HBOAR | D | SC | OMM. | |||||||
| Q _ | UW | UG O | RFUL | TZMAJ | I | AQ | UWW |
Cryptogram
| QUWUG | TKFAH | UWNWJ | LHNAR_ | QN GPU | PGNVF | ITROP | ERFER | OCBBC | LHSQH |
|---|---|---|---|---|---|---|---|---|---|
| SWOFZ | KDARQ_ | N NUNM | MYIDU | OQZKF | CNZNU | UWPWL | EXYHT | QUWUG | ORFUL |
| TZMAJ | IAQUW | W |
The cipher text in this example shows a tetragraphic and a pentagraphic repetition. The two occurrences of QUWUGc (=COMMAp) are separated by an interval of 90 letters; the two occurrences of ARQNc (=IRSTp) by 39 letters. The first repetition (QUWUGc), it will be noted, is a true periodic repetition, since the plaintext letters, their groupings, and the key letters are identical. The interval in this case, if counted in terms of letters, is the product of the keying cycle, 6, and the grouping cycle, 15. The second repetition (ARQNc) is not a true periodic repetition in the sense that both cycles have been completed at the same point, as is the case in the first repetition. It is true that ARQNc, representing IRSTp both times, is a causal repetition produced by the action of the same combination of key letters, I and G, but the enciphering points in the grouping cycle are different in the two occurrences. Repetitions of this type may be termed partially periodic repetitions, to distinguish them from those of the completely periodic type.
- c. When the intervals between the two repetitions noted above are more carefully studied, especially from the point of view of the interacting cycles which brought them about, it will be seen that, counting according to groupings and not according to single letters, the two pentagraphs QUWUGc are separated by an interval of 30 groupings. Or, if one prefers to look at the matter in the light of the keying cycle, the two occurrences of QUWUGc are separated by 30 key letters. Since the key is but 6 letters long, it has gone through 5 cycles. Thus, the number 30 is the product of the number of letters in the keying cycle (6) and the number of different-length groupings in the grouping cycle (5). The interaction of these two cycles is like that of two gears in mesh, one driven by the other. One of these gears has 6 teeth, the other 5, and the teeth are numbered. If the two gears are adjusted so that the teeth marked "1" are adjacent to each other and the gears are caused to revolve, these two teeth will not come together again until the larger gear has made 5 revolutions and the smaller one 6. During this time, a total of 30 meshings of individual teeth will have occurred. But since one revolution of the smaller gear (=the grouping cycle) represents the encipherment of 15 letters (when translated in terms of letters), the 6 complete revolutions of this gear mean the encipherment of 90 letters. This accounts for the period of 90, when stated in terms of letters.
- d. The two occurrences of the other repetition, ARQNc, are at an interval of 39 letters; but in terms of the number of intervening groupings, the interval is 12, which is obviously two times the length of the keying cycle. In other words, the key has in this case passed through two cycles.
- e. In a long message enciphered according to such a scheme as the foregoing, there would be many repetitions of both types discussed above (the completely periodic and the partially periodic) so that
3
the cryptanalyst might encounter some difficulty in his attempts to reach a solution, especially if he had no information as to the basic system. It is to be noted in this connection that if any one of the groupings exceeds, say, 5 letters or so in length, the scheme may give itself away rather easily, since it is clear that within each grouping the encipherment is strictly monoalphabetic. Therefore, in the event of groupings of more than 5 or 6 letters, the monoalphabetic equivalents of telltale words such as ATTACK, BATTALION, DIVISION, would stand out. This system is most efficacious, therefore, with short groupings.
f. It should also be noted that there is nothing about the scheme which requires a regularity in the grouping cycle such as that embodied in the example. A lengthy grouping cycle guided by a key of its own may just as easily be employed; for example, the number of dots and dashes contained in the International Morse signals 4 for the letters composing the 25-letter key phrase DECLARATION OF INDE-PENDENCE might be used. Thus, A (. -) has 2, B (_ ••• ) has 4, and so on. Hence:
D E C L A R A T I O N O F I N D E P E N D E N C E 3 1 4 4 2 3 2 1 2 3 2 3 4 2 2 3 1 4 1 2 3 1 2 4 1
The grouping cycle is 3+1+4+4+2+ , or 60 letters in length, and if the same phrase is used as a repeating key the total period would of course be 60, since after the encipherment of 60 letters the first key letter would be used again to encipher 3 letters, and so on, repeating the cycle. Suppose, however, that the foregoing 60-element keying pattern were used in conjunction with a different literal sequence for the actual key letters, say the 38-letter phrase CONSTITUTION OF THE UNITED STATES OF AMERICA. The period would then be the least common multiple of 38 and 60, or 1140 letters. This system might appear at first glance to yield a fairly high degree of cryptographic security; but this is not the case, as we shall presently see.
- 4. Primary and secondary periods; resultant periods.-a. It has been noted that the length of the complete period in a system such as the foregoing is the least common multiple of the length of the two component or interacting periods. In a way, therefore, since the component periods constitute the basic elements of the scheme, they may be designated as the basic or primary periods. These are also hidden or latent periods. The apparent or patent period, that is, the complete period, may be designated as the resultant or secondary period. In certain types of cipher machines there may be more than two primary periods which interact to produce a resultant period; also, there are cases in which the latter may interact with another primary period to produce a tertiary period, and so on. 5 The final, or resultant, or apparent period is sometimes the one which is usually ascertained first as a result of the study of the intervals between repetitions. This may or may not be broken down into its component primary periods.
- b. Although a solution may often be obtained without breaking down a resultant period into its component primary periods, the reading of many messages pertaining to a widespread system of secret communication is much facilitated when the analysis is pushed to its lowest level, that is, to the point where the final cryptographic scheme has been reduced to its simplest terms. This may involve the discovery of a multiplicity of simple elements which interact in successive cryptographic strata.
- 5. Cryptographic principles of aperiodic systems.-a. A discussion of the methods for avoiding periodicity was contained in the preceding text. 6A brief resume of these methods is given below:
- (1) Elements of a fixed or invariable-length key are applied to variable or irregular-length groupings of the plain text.
- (2) Elements of irregular-length (variable-length) key are applied to regular and fixed groupings of the plain text.
- (3) The principles of (1) and (2) are combined into a single system.
-SEBIIEI- 4
*4*Cf. p. 23, Military Cryptanalytics, Part I.
5An example of a cipher machine with several interacting latent periods is the Hagelin C-38. This machine produces in effect at any given moment six simultaneous reversed-standard-alphabet monoalphabetic substitutions in all 26 combinations of their presence or absence. The activity of each contributing monoalphabetic substitution is strictly periodic, with cycles of 26, 25, 23, 21, 19, or 17, conforming to the six regularly stepping pinwheels of the stated sizes. The total cycle of the machine is the product of the six relatively prime numbers, but the presence of individual subcycles constitutes one of the serious weaknesses of the machine.
6 Cf. par. 99, Military Cryptanalytics, Part II.
- (4) The key does not repeat itself; this is brought about either by constructing a nonrepeating key, or by employing the key in a special manner (such as in plaintext- and ciphertext interruptor systems and plaintext- and ciphertext autokey systems).
- b. From the standpoint of cryptographic mechanics, aperiodic systems may be divided into two main classes, viz.:
- (1) Systems in which the key elements are not in any way determined or influenced by any elements of the plain or cipher text; and
| (2) | Systems | in which | the key | elements | are genera | ted or | governed | by the | plain | text bein | g enciph | ıered |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| or by th | he resultar | nt cinher | text |
| or by the resultant cipner text. |
|---|
7 Cf. par. 65 (on p. 157) of Military Cryptanalytics, Part II.
(b)(1)
(b) (3) -18 USC 798
(b) (3) - 50 USC 3024(i)
(b) (3) - P.L. 86 - 36
CHAl'TER II
SYSTEMS USING CONSTANT-LENGTH KEYING UNITS TO ENCIPHER VARIABLE-LENGTH PLAINTEXT GROUPINGS
| Paragraph | |
|---|---|
| General remarks | 7 |
| Aperiodic encipherment produced by plaintext sequences grouped according to word lengths | 8 |
| Solution when known cipher alphabets are involved | 9 |
| Solution when unknown alphabets are involved | 10 |
| Solution by means of idiomorphs and the probable-word method | 11 |
| Solution by means of isomorphs | 12 |
| Additional remarks | 13 |
- 7. General remarks.-a. The system described in subpar. 3b is obviously not to be classified as aperiodic in nature, despite the incorporation into the cryptosystem of a variable which in that case consisted of irregularity in the length of one of the two elements (key text and plain text) involved in polyalphabetic substitution. The variable there was subject to a law which in itself was periodic in character.
- b. To make such a system truly aperiodic (under the definition given in subpar. le), by elaborating upon the basic scheme for producing variable-length plaintext groupings, would be possible, but impractical. For example, using the Morse code method illustrated in subpar. 3j for determining the key and simultaneously the lengths of the groupings, one might employ the text of a book; and if the book is longer than the message to be enciphered, the cryptogram would certainly show no periodicity as regards the intervals between any repetitions which might occur. However, as already indicated, such a scheme would not be very practical for regular intercommunication between a large number of correspondents, for reasons which are quite apparent. Encipherment and decipherment would be slow, cumbersome, onerous, and very subject to error; the book would have to be safeguarded as would a code book; and, unless the same key text were used for all messages, methods or indicators would have to be adopted to show exactly where encipherment begins in each message. Therefore a simpler method is desirable for producing constantly changing, aperiodic plaintext groupings.
- Aperiodic encipherment produced by plaintext sequences grouped according to word lengths. a. The simplest method for producing aperiodic plaintext groupings is encipherment according to the actual word lengths of the message being encrypted. Although the average number of letters composing the words of any alphabetical language is fairly constant, successive words comprising plain text vary a great deal in this respect, and this variation is subject to no law. 1 In telegraphic English, for example, the mean length of words is 5.2 letters; the words may contain from 1 to 15 or more letters, but the successive words vary in length in an extremely irregular manner, no matter how long the text may be.
- b. As a consequence, the use of word lengths for determining the number of letters to be enciphered by each key letter of a repetitive key suggests itself to a cryptographer as soon as he comes to understand the way in which repeating-key ciphers are solved. For, he asks, if there is no periodicity in the cryptograms, how can the letters of the cipher text written in 5-letter groups be distributed into their respective monoalphabets? And if this very first step is impossible, how can the cryptograms be solved? We shall see.
- Solution when known cipher alphabets are involved.-a. Despite the foregoing rhetorical questions, the solution is really quite simple when the cipher alphabets involved are standard alphabets or are otherwise composed of known sequences. All that is involved is the completion of the plain-component sequence (preceded by, if the situation so demands, conversion into plain-component equivalents). In monoalphabetic substitution systems, all of the words of the entire message come out on a single gen-
1 It is true, of course, that the differences between the vocabularies of two writers are often marked and can be measured. These differences may be subject to certain laws, but these laws are psychological rather than mathematical. See Rickert, E., New Methods for the Study of Literature, University of Chicago Press, Chicago, 1927.
eratrix in the completion diagram; in the case of the system discussed in subpar. 8b, since the individual, separate words of a message are enciphered by different key letters, these words will reappear on different generatrices of the diagram. All the cryptanalyst has to do is to pick them out; he can do this once he has found a good starting point, by using a little imagination and following clues afforded by the context.
b. As an example, let us consider the following intercepted message:
SUHPZ TCEPL GLQKC XHVKM VJLZA KXWHA YTOWN HBAFE XAVEQ AUVZI EBPOB
In the course of routine study of the message, the plain-component sequence is completed for the first 15 letters of the cryptogram, on the assumptions of direct and reversed standard cipher alphabets, as shown in Figs. 2a and b, respectively, below: 2
SUHPZTCEPLGLQKC TVIQAUDFQMHMRLD UWJRBVEGRNINSME VXKSCWFHSOJOTNF WYLTDXGITPKPUOG XZMUEYHJUQLQVPH YANVFZIKVRMRWQI ZBOWGAJLWSNSXRJ ACPXHBKMXTOTYSK BDQYICLNYUPUZTL CERZJDMOZVQVAUM DFSAKENPAWRWBVN EGTBLFOQBXSXCWO F H U C M G P R C Y T Y D X P GIVDNHQSDZUZEYQ HJWEOIRTEAVAFZR IKXFPJSUFBWBGAS J L Y G Q K T V G C X C H B T K M Z H R L U W H D Y D I C U LNAISMVXIEZEJDV MOBJTNWYJFAFKEW NPCKUOXZKGBGLFX OQDLVPYALHCHMGY PREMWQZBMIDINHZ QSFNXRACNJEJOIA RTGOYSBDOKFKPJB
SUHPZTCEPLGLQKC SKAGXVKOTOJPX IGTLBHYWLPUPKQY J H U M C I Z X M Q V Q L R Z KIVNDJAYNRWRMSA LJWOEKBZOSXSNTB MKXPFLCAPTYTOUC NLYQGMDBQUZUPVD OMZRHNECRVAVQWE PNASIOFDSWBWRXF QOBTJPGETXCXSYG RPCUKQHFUYDYTZH SQDVLRIGVZEZUAI TREWMSJHWAFAVBJ USFXNTKIXBGBWCK V T G Y O U L J Y C H C X D L WUHZPVMKZDIDYEM XVIAQWNLAEJEZFN YWJBRXOMBFKFAGO ZXKCSYPNCGLGBHP AYLDTZQODHMHCIQ BZMEUARPEINIDJR CANFVBSQFJOJEKS DBOGWCTRGKPKFLT ECPHXDUSHLQLGMU FDQIYEVTIMRMHNV G E R J Z F W U J N S N I O W
FIGURE 2a
FIGURE 2b
c. In the diagram in Fig. 2b we note the word CAN at the beginning of one generatrix, then in the very next six columns the words YOU and GET in two other generatrices. That we should get some three-letter words on various generatrices is not particularly remarkable; (note the short words produced purely by accident in the generatrices of Fig. 2a) but that these words should follow one another in direct sequence in succeeding columns, and that the three words in question should be in excellent contextual relationship to form a plausible and convincing sentence beginning such as "CAN YOU GET..."
<sup>2 One of the first things, if not the very first, to be done to a cryptogram in an undiagnosed system is the completion of the plain-component sequence on the basis of standard alphabets. In certain cases a solution is sometimes achieved by this means that would be impossible by any other. The completion is painless if accomplished by sliding strips; its probability of success in an isolated case is small, but the ratio of the time expended to its potential value is very large. This is a typical illustration of the application of the maxim of the experienced cryptanalyst: "Try the simplest thing first."
is more than remarkable (=a probability of .01 of random occurrence)—it is astonishing (=random probability of .0001).3
d. From here on the rest of the solution follows easily. If the cryptanalyst comes to a temporary halt (as in the example in Fig. 2b) in recovering further words on the generatrices, he can search in subsequent positions of the generatrix diagram for more words to be disclosed, and then he can fill in the missing portions from context and take another look at the generatrices. Or, it might be simpler if the cryptanalyst recovers a fragment of the specific key for the message, and then expands this key by steps to assist in reading the rest of the plain text. For example, in the case under discussion the cryptanalyst would get U, N, and I as key letters 4 for the successive words of the plain text CAN YOU GET; these letters suggest the words UNION, UNITED, UNIVERSITY, etc. The complete solution is given below, with the recovered specific key being UNITED NATIONS.5
U N I T E D N A T I O N S CAN YOU GET IN TOUCH WITH SECOND DETACHMENT STOP LINES OUT OF ORDER SUH PZT CEP LG LQKCX HVKW VJLZAK XWHAYTOWNH BAFE XAVEQ AUV ZI EBPOB
The only minor difficulty of such a solution is that of making the first step and getting a good start on a word. If the words are short it is rather easy to overlook good possibilities and thus spend some time in fruitless searching. However, solution must come; if nothing good appears at the beginning of the message, search should be made in the interior of the cryptogram or at the end.
- Solution when unknown cipher alphabets are involved.—a. It has been seen from the foregoing that solution of cryptograms involving word-length encipherment by standard alphabets is rather trivial, not because there is any magical quality about standard alphabets, but because the components are known sequences. If any other components had been used, say a plain component based upon a HYDRAULIC keyword-mixed sequence and a cipher component based on a QUESTIONABLY keyword-mixed sequence, and if these components were known, the problem would have been pursued in exactly the same way, viz., conversion of the cipher letters of the cryptogram into their plain-component (HYDRAULIC . . . XZ) equivalents and completion of the plain-component (HYDRAULIC . . . XZ) sequence.
- b. But what if one or both of the components are unknown mixed sequences? The simple procedure of completing the plain-component sequence obviously cannot be used. Since the messages are polyalphabetic, and since the process of factoring cannot be applied, it would seem that the solution of messages enciphered in different alphabets and according to word lengths would be a difficult matter. Nevertheless, as is about to be demonstrated, the solution, even of a single message, is not nearly so difficult as first impression might lead one to imagine; the modus operandi will be explained in pars. 11 and 12.
- Solution by means of idiomorphs and the probable-word method.—a. The first case to be studied involving unknown alphabets will be one wherein the original word lengths are retained in the cryptogram; this case will be discussed not because it is often encountered in practical military cryptography, but because it affords a good introduction to the usual case in which the original word lengths are no longer in evidence in the cryptogram, the latter appearing in the customary 5-letter groups. If the words
---SEORET-
<sup>3 We must never forget that probabilities are influenced by the amount of material under examination; if we looked at enough material, it might not be at all astonishing if we obtained even a 10-letter word by accident. In all the probability considerations in this text, unless otherwise stated it is assumed that we are dealing with a limited amount of traffic, limited enough so that a probability of .01 is remarkable, and a probability of .001 exciting.
<sup>4 The key letters are assumed to be under $A_p$ as the index letter. Throughout this text, whenever encipherment processes are under discussion, the pair of enciphering equations commonly referred to as characterizing the so-called Vigenère method will be understood unless otherwise indicated. This method involves the pair of enciphering equations $\theta_{k/2} = \theta_{i/1}$ ; $\theta_{p/1} = \theta_{e/2}$ . That is, the index letter, which is usually the initial letter of the plain component, is set opposite the key letter in the cipher component; the plaintext letter to be enciphered is sought in the plain component and its equivalent is the letter opposite it in the cipher component. See in this connection subpar. 13f of Military Cryptanalytics Part II.
<sup>5 This is the specific key as recovered from this single message. It is quite possible that the complete key is UNITED NATIONS ORGANIZATION, UNITED NATIONS SECURITY COUNCIL, etc.; a longer message would prove whether the key is UNITED NATIONS used repetitively, or whether it is a phrase beginning with these two words.
SECRET-
of a message are enciphered monoalphabetically, the true and complete idiomorphs of word patterns will be patent, regardless of the identity of the particular alphabet used in the encryption of each word. These idiomorphs and word lengths can then be used as a basis for the probable-word method of attack.
b. Let us study the following low-echelon ground message in which the actual word lengths have been preserved in the cipher text:
IUITD QHIWE LVCGWPCLZ RP NIV GYPYSYCV NC IXHCXWUJ ORS ZXH GRPPRVQDOB SE OKYNMMHKV GUJLTN MYIN WZ IVURNI CLSWZVHS
We note some strong idiomorphic sequences, in particular the following:
(1) $\frac{\text{IUITD}}{\text{aba}}$ (2) $\frac{\text{GYPYSYCV}}{\text{abaca}}$ (3) $\frac{\text{GRPPRVQDOB}}{\text{abba}}$ (4) $\frac{\text{OKYNMMHKV}}{\text{abcddea}}$
Looking up these patterns in idiomorph lists,7 and guided by the delimitations of the words, we arrive at the following assumptions:
(1) IUITD (2) GYPYSYCV (3) GRPPRVQDOB (4) OKYNMMHKV ENEMY DIVISION BATTALIONS ARTILLERY
The cipher values of these plain-cipher equivalencies are entered into a sequence reconstruction matrix of four levels (representing the four word assumptions), as follows:
| P: | A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (1) | I | T | U | D | ||||||||||||||||||||||
| (2) | G | Y | ٧ | C | S | P | ||||||||||||||||||||
| (3) | R | G | Q | V | 0 | D | В | Р | ||||||||||||||||||
| (4) | 0 | Н | N | M | K | Y | V |
FIGURE 3a
Noting in lines (2) and (3) that the intervals between the letters G, V, and P are the same in both cases, we can assume direct symmetry 8 of position. In a few moments our reconstruction matrix will look like this:
| P: | Α | В | C | D | E | F | G | Н | Ι | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (1) | s | Н | В | P | I | N | M | R | G | Т | U | K | Y | Q | ٧ | C | 0 | D | ||||||||
| (2) | M | R | G | T | U | K | Y | Q | ٧ | C | 0 | D | S | Н | В | P | I | N | i | |||||||
| (3) | R | G | T | U | K | Y | Q | V | C | 0 | D | S | Н | В | P | Ι | N | M | ||||||||
| (4) | 0 | D | S | Н | В | P | I | N | M | R | G | T | U | K | Y | Q | V | C |
FIGURE 3b
c. The rest of the plain text can be recovered either by (1) completion of the plain-component sequence, insofar as possible, in order to reveal further plaintext fragments which may be expanded and thus make possible the filling in of additional values in the cipher component, or by (2) recovery and expansion of the partial specific key for the message. An important additional step in solution is the recovery of the missing letters in the cipher component by analysis of the construction of the component in cases of systematic derivation. These points will be taken up in order in the subparagraphs below.
<sup>6 Foolish as this may be, it has happened in operational practice.
<sup>7 Cf. Appendix 3, Military Cryptanalytics, Part I.
<sup>8 Cf. par. 28, Military Cryptanalytics, Part II.
(1) Let us complete the plain-component sequence on the second and third words of the message, after first converting the cipher letters into their plain-component equivalents (where known), using for this purpose the uppermost cipher alphabet given in Fig. 3b. This is shown in the illustration below:
| IUITD | QHIWE | LVCGWPCLZ | LVCGWPCLZ | LVCGWPCLZ | |||
|---|---|---|---|---|---|---|---|
| ENEMY | SBE | VWL OW | GVWL OW | HVWL OW | |||
| TCF | WXM EX | HWXM EX | IWXM EX | ||||
| UDG | XYN FY | IXYN FY | JXYN FY | ||||
| VEH | YZO GZ | JYZO GZ | KYZO GZ | ||||
| WFI | ZAP HA | KZAP HA | LZAP HA | ||||
| XGJ | ABQ IB | LABQ IB | MABQ IB | ||||
| YHK | BCR JC | MBCR JC | NBCR JC | ||||
| ZIL | CDS KO | NCDS KO | OCDS KO | ||||
| AJM | *DET LE | ODET LE | POET LE | ||||
| BKN | EFU MF | PEFU MF | QEFU MF | ||||
| *CLO | FGV NG | QFGV NG | RFGV NG | ||||
| DMP | GHW OH | RGHW OH | SGHW OH | ||||
| ENQ | HIX PI | SHIX PI | THIX PI | ||||
| *FOR | IJY QJ | TIJY QJ | UIJY QJ | ||||
| GPS | JKZ RK | UJKZ RK | VJKZ RK | ||||
| HQT | KLA SL | VKLA SL | WKLA SL | ||||
| IRU | LMB TM | WLMB TM | XLMB TM | ||||
| JSV | MNC UN | XMNC UN | YMNC UN | ||||
| KTW | NOD VO | YNOD VO | ZNOD VO | ||||
| LUX | OPE WP | ZOPE WP | AOPE WP | ||||
| MVY | PQF XQ | APQF XQ | BPQF XQ | ||||
| NWZ | QRG YR | BQRG YR | CQRG YR | ||||
| OXA | RSH ZS | CRSH ZS | DRSH ZS | ||||
| PYB | *STI AT | DSTI AT | *ESTI AT | ||||
| QZC | TUJ BU | ETUJ BU | FTUJ BU | ||||
| *RAD | UVK CV | FUVK CV | GUVK CV | ||||
| FIGURE 4a | FIGURE 4b | FIGURE 4c |
The generatrices with the most plausible possibilities for the continuation of plain text are marked with an asterisk. If the context of the message cannot be gotten from this diagram, what we can do is to take the third word, LVCGWPCLZ, and assume that the letters for which we have no plain-component equivalents in the first cipher alphabet of Fig. 3b represent one of the eight missing plaintext letters, G, H, J, P, R, T, U, or Z. If we assume that the first letter (Le) of this word represents GP (on the first or conversion row of the generatrix diagram just beneath the ciphertext letters), we obtain the result shown in Fig. 4b; when we try Lc=Hp, as shown in Fig. 4c, we obtain an excellent plaintext tetragraph on the third generatrix from the bottom, and see that the word is ESTIMATED. The newly recovered values in the cipher alphabet will aid in establishing the remaining unknown letters in the generatrix diagrams for other words of the message.
(2) For the second method, let us refer again to Fig. 4a. The key letter used to encipher the first word, ENEMY, is Sk (assuming AP to be the index letter in the usual Vigenere equation), since Ic=EP. Now for the second word, if Q0=Cv (one of the asterisked good generatrices for this word), the key is Yk; if Qc=F P, Bk=U; and if Qc=Rp, Bk=H. The first key digraphs thus formed, SY, SU, and SH, are all compatible as English word beginnings. For the third word of the message, considering the two asterisked generatrices in Fig. 4a, if Vc=Dp, Bk=Q; if V0 =Sp, Bk=P. Therefore the first three key letters are now resolved as SYP or SUP; SYP is quickly discarded, and SUP should be followed by an E, I (less likely), P, or R, suggesting words such as SUPERIOR, SUPPORT, or SUPREME. A quick check on the message establishes that, with Bk=R, the fourth word deciphers to ATP. Proceeding in this fashion, we are able to recover the key and simultaneously the plain text in record time.
11 BFCBil
SECR!T
(3) In cases wherein the cipher component has been constructed in some systematic manner, analysis of its derivation will make possible recovery of the component in its entirety after a sufficient number of values has already been placed correctly. 9What constitutes "a sufficient number of values" depends upon the type of construction of the component, as well as the vagaries of the particular situation at hand. Taking for example the cipher component as established in Fig. 3b,
S H B P I N . . M . R G T U K . Y . Q . . V C O D
we observe the digraphic fragments BP and GT. If these are a part of a transposition-mixed sequence, the mechanics of the system would indicate that the fragments are part of the diagram B . . . G, P Q R S T
which means that three of the letters CDEF lie in order between Band G, and that directly above them are the letters composing the key word for the transposition matrix. However, since R immediately precedes the G in the sequence, it appears that R is part of the key word and not part of the remaining
HY DR
alphabetic portion. Thus the fragmentary matrix B . . G can be reconstructed, from which, with but P Q S T
little imagination, the key word HYDRAULIC may be seen emerging, so that the entire component is derivable from the following diagram:
4 9 3 7 1 8 6 5 2 H Y D R A U L I C B E F G J K M N 0 P Q S T V W X Z
d. By means of the foregoing methods, we can establish that the primary components are the following:
P: ABC DEF G HI J KL MN OP QR STU V W X Y Z C: A JV COD F SH BP IN Z L M X R GT UK WYE Q
The complete message and the specific key are given below:
s u p R E M E C 0 u ENEMY FORCE ESTIMATED AT ONE DIVISION OF INFANTRY AND TWO IUITD QHIWE LVCGWPCLZ RP NIV GYPYSYCV NC IXHCXWUJ ORS ZXH
R T 0 F T H E u BATTALIONS OF ARTILLERY MOVING WEST OF NEWTON JUNCTION GRPPRVQDOB SE OKYNMMHKV GUJLTN MYIN WZ IVURNI CLSWZVHS (NITED STATES)
Now that the components have become known sequences, the solution of subsequent messages enciphered with these components but with different specific keys is a simple matter, involving only a conversion of the cipher letters into their plain-component equivalents and a completion of the plaincomponent sequence. This point required re-emphasizing because in actual operational problems it is frequently forgotten.
e. The example in subpar. b involved a case of direct symmetry of position. If both the plain and the cipher components had involved mixed sequences, indirect symmetry of position would have
9For a treatment of the cryptographic mechanics of systematically mixed sequences and their cryptanalytic recovery, see par. 51 (on pp. 86-90) of Military Cryptanalytics, Part I.
applied.10 As an example of such a case, let us suppose that the cipher text of the message in question had been different, and that the sequence reconstruction matrix in Fig. 3a had been the following:
| ø | A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Н | U | L | _ | 0 | |||||||||||||||||||||
| 2 | J | P | Y | D | U | Ι | ŀ | |||||||||||||||||||
| 3 | R | C | L | U | M | N | Q | S | ||||||||||||||||||
| 4 | 0 | W | S | Q | N | C | K | ] |
FIGURE 5
(1) We observe the proportion AR $(\emptyset-1, 3-1) = 0$ N $(\emptyset-15, 3-15)$ which is duplicated in AR $(\emptyset-1, \emptyset-18) = 0$ N (4-1, 4-18); 11 this is indicative that symmetry extends to the $\emptyset$ line, and therefore that the plain and cipher components are identical sequences. Consequently, we are able to chain to the $\emptyset$ line, deriving the following sets of partial chains:
| Ø-1 | E | Н | M | U | N | L | Y | 0 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ø-2 | 0 | D | J | V | I | P | N | Y | S | U | ||||||||||
| Ø-3 | A | R | В | C | I | L | U | 0 | N | M | T | S | Q | |||||||
| Ø – 4 | A | 0 | E | W | I | S | L | Q | R | N | Т | C | Y | • | K |
FIGURE 6
(2) We note that the fragmentary chains ONM and TSQ of the $\emptyset$ -3 set appear to be parts of a keyword-mixed sequence in reverse; so, proceeding with the graphical method 12 of indirect symmetry, we assign to these chains the notation $\rightarrow$ , and then we arbitrarily assign the notation $\downarrow$ to the $\emptyset$ -2 chains. The four sets of fragmentary chains will then be amalgamated into the diagram shown in Fig. 7a, below.
| C | В | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q | S | T | V | J | K | M | N | 0 | P | Q | S | T | V | |||||||||||||||||
| U | L | I | Y | D | R | Α | Ü | L | Ι | C | В | |||||||||||||||||||
| K M | N | 0 | P | J | K | M | N | 0 | P | Q | S | T | V | |||||||||||||||||
| Y | D | R | A | - | ||||||||||||||||||||||||||
| J | ||||||||||||||||||||||||||||||
| F | (GU | RE | 7a | Fi | GU | RE | 7b |
This diagram may then be expanded into that shown in Fig. 7b, consisting of the integration of two major chains tied together by the vertical VIP relationship.
(3) Now noting in Fig. 7b the sequence VCS on a diagonal and the letters S.V in the top row, we realize that the distance V to C when measured on the primary component should be 12, i.e., one-half of the distance (24) between V and S on the top row. Consequently, we may place the C at a position 12 spaces to the right of the V, which permits us to expand our diagram into the following:
$$\begin{array}{cccccccccccccccccccccccccccccccccccc$$
FIGURE 7c
(4) The fragmentary chains EH and EW in Fig. 6 could have been placed in their proper positions earlier in Figs. 7a-c; however, in order to illustrate a point, we have delayed their amalgamation until now. We note that the $\emptyset$ -1 chains in Fig. 6 are at a decimation of -10 in the sequence in Fig. 7c; there is only one possible placement of the letters E and H at this interval, which then fixes the position of the
SECRET
10 Cf. Chapter VI, Military Cryptanalytics, Part II.
11 This notation has been discussed in footnote 2 on p. 92, Military Cryptanalytics, Part II.
12 Cf. par. 46, Military Cryptanalytics, Part II.
last unused letter, W, the placement of which heretofore could have been ambiguous. ThesP. letters fit into the reconstructed sequence as follows:
J K M N O P Q S T V W . H Y D R A U L I C B E . .
It is a pleasure to use, without encountering a risk of cavilation the word "obvious" 13 as regards the positions of the missing letters:
J K M N O P Q S T V W X Z H Y D R A U L I C B E F G
- j. The immediately preceding example treated a case of identical sequences proceeding in the same direction for the plain and cipher components. If the cipher component had run in the reversP- direction, or if the components had been two different [unknown) mixed sequences, indirect symmetry would still have applied, with the exception (and a very important exception indeed) that chains to the 0 line would have been excluded, all chaining being done within the matrix. This prohibition would result in the situation that not only would a ,-,ingle short message encrypted in such a system be well-nigh unsolvable, but that even if we had a long message or a small volume of traffic, it would probably be necessary to make a fairly large number of assumptions, all correct, before there would be enough data available to permit their manipulation and exploitation by indirect ,;ymmetry.
- g. Now that we have understood the details of solution of cases wherein the true word lengths have been preserved, we will take up the situation wherein the cipher text has been tran,;mitted in its usual form of 5-letter groups.
- (1) Let us suppose that we have a number of messages, all of which are known to have been enciphered monoalphabetically by word lengths with the same pair of unknown primary mixed components and (although this is not a vital consideration) in the same message key. 14 Five messages have been select,ed from the aggregate because of the presence of polygraphic repetitions between them; the beginnings of these messages are shown in Fig. 8a, below:
- G K B S A M K U H Q P J C G K K L J H K C F V T Y 2. A L E. J Q A K G L Y L W H R H C D H K U V B V P V 3. S T T J U M A M K U Z I U V S V N R L Z O K L Z P 4. L K Q A M G I J E U M G P J C G K K L J H B E K V
FIGURE Sa
- B K J U A I E S A A S B R H S L Y L W H H Q Y E P
14 If this latter fact had not been known, it could have been conjectured, from an examination of the I.C.'s of groups of columns, that the same message key was used for ull the messages. In the particular example in Fig. Sa, the LC. of the first ;; columns (taken collectively) is 1.56, while that of the first 10 is 1.76, and thereafter the I.C. drops off very rapidly even though we arc adding more data to our distribution for evaluation. The grouped I.C.'s for the first N columns are summarized in the diagram below:
| N | LC. | N | I.C. |
|---|---|---|---|
| 5 | 1. 56 | 12 | 1. 53 |
| 6 | I. 55 | 15 | I. 33 |
| 8 | 1. 73 | 20 | 1. 37 |
| iO | 1. 76 | 25 | 1. 24 |
The reason for the low I.C.'s of the first 5 and the first 6 columns is that the sample was insufficient to portray what we expect of English plain text; on the other hand, the reason for the high I.C.'s of the first 8 and the first 10 columns is that the beginning words of these messages probably exceed the average length (.5.2 letters) of all English words.

13 The reader is reminded of the pithy anecdote on the word "obvious" quoted in footnote 11 on p. 6 of J'tfilitary Cryptanalytics, Part I.
(2) The 5-letter and 9-letter repetitions have the length and idiomorphic patterns of ENEMY and ARTILLERY, respectively. Taking into account that the average word length in telegraphic English plain text is 5.2 letters, it appears that both of these words were probably enciphered by the third letter of the message key, 15 although the relative numerical identity of the particular alphabet is really of no concern to us at the moment. On the basis of the idiomorphic beginning, Message No. 3 could start with the word AMMUNITION, making the 4-letter repetition TION which is cryptolinguistically titillating; the first word of Message No. 1, LOCATION, comes immediately thereafter, which is followed by COUNTERATTACK at the beginning of Message No. 5, HOSTILE at the beginning of Message No. 4, and THRUST at the beginning of Message No. 2. From the solution of the first three words of these five messages, and with the concurrent exploitation of the direct symmetry manifested, the primary cipher component is established as
S H B P I . Z L M . R G T U K W Y E Q A J V C . D F
(3) The key letters (under Av) of the first three alphabets are S, U, and P. The rest of the solution proceeds either by the generatrix method as outlined in subpar. llc(l), or by analysis of the key as illustrated in subpar. llc(2). The complete texts of the message beginnings are shown in Fig. 8b, below:
| 1. | G K B S A | MK UIH QI | p JC GK | KL J HIK | C F V R T |
|---|---|---|---|---|---|
| L O C A T | I O N O F | A R T I L | LE RYE | M P L A C | |
| 2. | A L E J Q | AIK GIL y | L w HIR H | CD HK uni | VB V p V |
| T H R U S | T B Y E N | EM YA R | M O R E | E L E M E | |
| 3. | S T T J U AM MUN |
0 KL ZIP U L E D T |
|||
| 4. | LKQ AM | G IIJ Eu | M GIP JC | G K K L J | HIB EK V. |
| H O S T I | LEH EA | V Y A R T | I L L E R | Y S H E L | |
| 5. | B K J U A C O U N T |
I E S A A E R A T T |
s | A C K O N E N E M Y R I G H | B RJH s1 LY L w HI HQ YE zTj. |
FIGURE Sb
- (4) It may be seen from the foregoing example that the general theory of idiomorphic attack and the probable-word method remains the same for 5-letter texts as it is for text divided into bona fide word lengths; only the details of the execution differ. Where a small volume of homogeneous traffic is at hand, and something is known about the correspondents and the nature of the messages, solution should pose no problems (other than usual cryptanalytic headaches concomitant with operational situations of minor systems in which only a few messages are available).
- Solution by means of isomorphs.-a. The phenomenon of isomorphism and an illustration of the exploitation of isomorphs in cipher text were covered in the previous volurne. 16 In practical cryptanalysis the phenomena of isomorphism afford a constantly astonishing source of clues and aids in solution. The alert cryptanalyst is always on the lookout for situations in which he can take advantage of these phenomena, for they are among the most interesting and most important in cryptanalytics.
---------------------------------
'" We have already noted that the common plain-cipher equivalencies Ev=L0 and Yv=H. in the two words establish the fact that these words were enciphered by the same alphabet.
16Cf. par. 71, Military Cryptanalytics, Part II.
b. Let us consider the case of word-length encipherment involving an unknown pair of primary components, the cipher text being transmitted in the customary 5-letter groups. The following cryptogram is available for study:
c. There are no long polygraphic repetitions in evidence. An isomorphic search, 17 however, uncovers several isomorphic sequences indicated by the dotted lines above; these are grouped into the following two sets of isomorphs:
| 5 | Set | "1 | A " | 1 | Set | ; " ] | В" | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $(\alpha)$ | L | Н | J | J | T | Y | Z | L | D | X | Z | Н | Y | $(\delta)$ | D | F | G | 0 | 0 | В | D |
| (β) | P | G | Z | Z | I | J | F | P | K | E | F | G | J | $(\epsilon)$ | T | A | U | E | E | D | T |
| $(\gamma)$ | D | V | В | В | 0 | W | T | D | X | S | T | V | W |
If these isomorphs are causal isomorphs, i.e., isomorphs produced by the different encryptions of identical plaintext sequences, then the relationships between corresponding letters of the isomorphs reflect the relationships between different juxtapositions or slides of a cipher component against a plain component; these relationships, latent in the isomorphs, may be made patent through the mechanics of indirect symmetry.
d. The partial chains derivable from these isomorphs are given below:
$$\alpha$$
- $\beta$ : L P H G Y J Z F T I D K X E $\alpha$ - $\gamma$ : L D X S H V J B Z T O Y W $\beta$ - $\gamma$ : P D G V Z B I O J W F T K X E S $\delta$ - $\epsilon$ : B D T F A G U O E
Using the graphical method of indirect symmetry, these partial chains may be amalgamated into the diagrams shown in Figs. 9a and b, below. We note in Fig. 9a the $\begin{picture}(1,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0) \put(0,0)$
OP, and EF, and conclude that the cipher component must be a keyword-mixed sequence. We now expand the diagram of Fig. 9a by placing the W in position diagonally ahead of the XZ, and we duplicate the remaining letters in their proper position with respect to the W just placed a moment before; this
| Y W | Y W | Y W | |
|---|---|---|---|
| JB LDXS ZTO PKE FI A |
H V . G U FIGURE 96 | . J B Y W L D X S S F I Z T O A P K E F I | . H(V) JB Y(W). LD(X)S G (Z)TOJBU PKELDXS FI ZTO A PKE FI |
| A Figure 9c |
A Figure 9d |
<sup>17 For a systematic method of searching for isomorphs, see footnote 7 on p. 174 of Military Cryptanalytics, Part II.
is shown in Fig. 9c. This facilitates placing the diagram of Fig. 9b into the array (on the basis of the VWXZ diagonal), resulting in the final diagram shown in Fig. 9d. From this latter figure, the original cipher component, minus 5 letters, may be chained out:
$$\begin{array}{cccccccccccccccccccccccccccccccccccc$$
Our old friend HYDRAULIC.
- e. We have the sequence for the cipher component, but now what? We could assume the plain component to be the normal sequence, direct and then reversed, and we could convert the first few cipher letters into their plain-component equivalents on these hypotheses and then complete the plaincomponent sequence; if we are correct in our assumption, a plaintext word would be revealed on one generatrix, another word on a different generatrix, etc. We could also assume the plain component to be the same as the cipher, in the same or in the reverse direction, and we could complete the plain-component sequence accordingly. All of these attempts fail, so it means that we are faced with a plain component of unknown composition. We have the cipher component at hand, it is true, but unless we know or can deduce the motion of the cipher component, 18 it will be impossible for us to convert the cipher text into monoalphabetic terms; in other words, the original cipher is already reduced as far as it will go. Plaintext assumptions are now an absolute necessity.
- f. It can be seen by referring to the two sets of isomorphs in sub-par. c that Set "A" has the complete idiomorphic pattern for COMMUNICATION, and that Set "B" has the idiomorphic pattern contained in ARTILLERY. If the now known cipher component is set down and the plaintext equivalents for the first occurrences of the assumed COMMUNICATION and ARTILLERY are recorded in the rows labelled P1 and P2 of the diagram below, direct symmetry of position will of course apply, provided that there
$$\begin{array}{cccccccccccccccccccccccccccccccccccc$$
is a tie-in letter between the sequences; there happen to be three such letters, so that the plain component may be expanded as follows:
ONA.LYC ...... M.R ..... UE.TI
Since there are manifested the phenomena of a keyword-mixed sequence in the plain component, we may further expand the sequence into the following:
ONA.LYCDFGHJKM.R ..... UE.TI
If the key word for the sequence cannot be guessed from this partial sequence, we might finish the solution by a modification of the method indicated in subpar. llc(l), with the difference that, in this case, not only will some of the cipher letters not have plain-component equivalents, but also that the plain component itself will have gaps in its sequence in the plain-component completion diagram. After the key word ( QUESTIONABLY) for the plain component has been recovered, the solution can be completed by the generatrix method, keeping in mind the reconstruction of the message key as a means of quick
18 See in this connection subpar. 71d on p. 175 of Military Cryptanalytics, Part II.
- SEGRET
analysis after a few letters of the key have been derived. The complete decipherment of the message is shown below:
FIGURE 10
The key for the message, under $Q_p$ as the index letter, is "STRIKE WHILE THE IRON IS . . . (HOT?)" 19
g. In connection with the solution of the problem in this paragraph, let us take a closer look at the isomorphs listed in subpar. c. These are given below, together with their plaintext equivalents:
| Set "A" | Set "B" | |
|---|---|---|
| COMMUNICATION | (A)RTILLER(Y) | |
| $(\alpha)$ | LHJJTYZLDXZHY | (δ) D F G O O B D |
| ( \beta) | PGZZIJFPKEFGJ | (e) TAUEEDT |
| $(\gamma)$ | DVBBOWTDXSTVW |
In case it had escaped attention before, note the ciphertext fragments XZHY, EFGJ, and STVW at the ends of the isomorphs of Set "A". These three tetragraphs, transparent in the cipher text, are actually fragments of the keyword-mixed sequence constituting the cipher component. The reason for their presence is not hard to find: the plaintext equivalent of the isomorphs ended with TION and the letters TION happened to be a fragment of the keyword-mixed sequence constituting the plain component. (Note also, from Set "B", that AU must also be in sequence in the cipher component.) This information would have been of assistance to us in the chaining process pursued in subpar. d; for pedagogical reasons, however, we delayed drawing attention to this situation until now. Needless to say, this situation or a recognizable variation of it could be of considerable assistance in the solution of a difficult problem of only a few messages in actual operations.
h. One more very important facet of isomorphism should be discussed at this point. Let us suppose that we have recovered the cipher component of the message under study through the exploitation of isomorphs as just demonstrated; but let us suppose that the two plaintext assumptions (COMMUNICATION and ARTILLERY) were insufficient to disclose enough of the sequence for the plain component to permit its facile recovery.20 Additional plaintext assumptions are necessary, but we seem to have milked the
19 Hot.
<sup>20 This would be the case if the plain component were not a keyword-mixed sequence but were, let us say, a transposition-mixed sequence.
cipher text dry with the two cribs we have already placed. The problem confronting us is how to make further "educated guesses" that might display a trace (or more, we hope) of erudition.
i. Since the cipher component has become a known sequence, let us set it down, numbering its elements serially from 1 to 26, as follows:
$\begin{array}{cccccccccccccccccccccccccccccccccccc$
Let us first replace the letters of the cipher text by their numerical equivalents according to the HYDRAULIC sequence. We will then take a delta or lateral difference stream 21 from these numerical values, by subtracting each number from the following one; 22 however, instead of recording the numerical difference, we will record the literal equivalent of this numerical difference according to the HYDRAULIC sequence above. The result of this process is shown in Fig. 11, below:
| 7 | 1 | 14 | 14 | 22 | 2 | 26 | 7 | 3 | 25 | 26 | 1 | 2 | 19 | 1 | Z 26 X |
12 | 18 | 9 | 25 | 7 | 8 | 16 | 3 | 12 | 13 | 18 | 18 | 10 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P 19 M |
12 | 20 | X 25 A |
25 | 20 | 13 | 2 | 14 | 19 | 4 | 25 | 13 | 14 | 13 | L 7 Q |
22 | 21 | 4 | 16 | 15 | 21 | 19 | 13 | 26 | Z 26 Z |
8 | 14 | 12 | 19 |
| 11 | 12 | 18 | 14 | 16 | 15 | 1 | 8 | 2 | 3 | 9 | 9 | 22 | 5 | 6 | 11 | E 11 Z |
3 | 22 | 12 | 15 | 1 | 6 | 12 | ||||||
| 21 | 18 | R 4 N |
13 | 11 | 13 | 15 | 10 | 24 | 25 | 24 | 3 | 23 | 10 | 10 | 18 | 24 | 22 | 3 | 25 | 21 | T 22 H |
23 | 24 | 16 | 22 | ||||
| 12 | 10 | 8 | J 14 E |
26 | 8 | 2 | Z 26 W |
10 | 11 | X 25 J |
25 | 25 | 25 |
FIGURE 11
j. We can see, by comparing Fig. 11 with the original plain text as given in Fig. 10, that the delta stream has revealed all of the polygraphic repetitions of trigraphs or better in the underlying plain text.23 Note the IXF repetition in the delta stream, which means that the ciphertext sequences PHZF and IMKH must represent the same plain text (probably the word WITH, since it is a four-letter repetition following COMMUNICATION); the PHZF and IMKH sequences are actually isomorphic, but we were unable to recognize them as such until now. Also note the delta repetition FAESJH, which means that the ciphertext sequences YJPRXGJ and KHUNFZH (an isomorphic pair whose isomorphism we were unable to trust before, because of a lack of sufficient corroborative values in the isomorphic repetition pattern) must represent the same plain text (in this case, the assumption of the word THROUGH would be permitted). Note further the HH digraphic fragment in the delta stream, which means that GJKc must represent IONp (from COMMUNICATION); since this is not preceded by Tp, the assumption of Sp and therefore DIVISION is encouraged. With these plaintext values and those which follow as a direct result of our analysis thus far, it would be a simple matter to reconstruct the plain component almost in toto and the plain text of the message in its entirety.
- Additional remarks.—a. One of the practical difficulties in employing systems in which the keying process shifts according to word lengths is that in handling such a message the deciphering clerk is often not exactly certain when the termination of a word has been reached, which results in the loss of time and effort. For instance, in deciphering a word such as INFORM, the clerk would not know whether he now has the complete word and should shift to the next key letter or not; the word might be INFORMS,
<sup>21 The application of delta stream techniques to the solution of digital cipher systems has been illustrated in Chapters XI and XII of Military Cryptanalytics, Part II.
<sup>22 In this process, subtraction is performed mod 26: i.e., if we are to subtract a large number from a smaller, we add 26 to the smaller before subtraction. For example, 1-7=(1+26)-7=20=Q in the scale above. 26 is equivalent to $\emptyset$ in this modulus, so that $14-14=\emptyset=Z$ .
<sup>23 The plaintext repetitions are foreshortened by one letter in the delta stream; e.g., COMMUNICATION, a 13-letter word, appears as a 12-letter sequence in the delta stream.
INFORMED, INFORMING, INFORMAL, INFORMATION, etc. The past tense of verbs, the plural of nouns, and terminations of various sorts capable of being added to word roots would give rise to difficulties, and the latter would be especially troublesome if the messages contained a few telegraphic errors to boot. Consequently, word separators are often adopted to circumvent this source of trouble.24 These separators usually consist of an infrequent letter, such as $X_p$ or $Q_p$ , which is placed after every word of the plain text and is encrypted along with the rest of the message.25
(1) When word separators are employed and this fact is once suspected or discovered, their presence is of as much aid to the cryptanalyst in his solution as it is to the clerks who are to decipher the messages. As an example, let us study the following cryptogram:
| IWJIR | NPTXS | FIWCM | SDFEW | SBLXQ | LBHFL | TYIFD | UVLUL | JRLYG | HRZYI |
|---|---|---|---|---|---|---|---|---|---|
| FMZXD | GRMCR | SWPTX | SFIWC | KAMWZ | XLXWQ | BAARN | FLTVQ | AMQDZ | LVUQK |
| GQZZ0 | IHMIR | OLOMI | DXZFG | PLKIS | CAHQZ | MGNWX | BTIYQ | BDLTP | NPQUD |
| LYLGU | FINSX | LOHZA | SXAFD | XTFIZ | PJXMM | QDCPE | WYIBZ | QGHBH | RXDTX |
| IOOLU | IKVGC | MGITZ | HWDRG | GIWMY | RZWNP | FDCEM | YFASY | PJWHX | JZGWW |
| XFQXO | TMCNA | UUEJJ | IKVGH | RZYIP | MWIDL | RDCWI | PGAQC | SACWP |
Collateral information indicates that the cryptosystem involves monoalphabetic encipherment by word lengths, a word separator being used to signal the change to a new key letter; the key letters themselves form a plaintext word as a mnemonic key.
(2) If the encipherment is by word lengths and a word separator is used, the average length of words should be 6.2 letters. Since a key word is used to control the selection of alphabets, if a polygraphic repetition of significant length is present in the cipher text, the interval between the first and second occurrences should give a fair indication of the length of the key, unless there are repeated letters in the key and these polygraphic repetitions happen to be produced by identical key letters in different positions in the key word. We note the 8-letter repetition PTXSFIWC at an interval of 56 letters; this would seem to indicate that the key word is $\frac{56}{6.2}$ or 9 letters long, give or take a letter. Since there is another
polygraphic repetition present, GHRZYI at an interval of 224 letters, the division $\frac{224}{6.2} = 36 = 4 \times 9$ furnishes corroboration of the length of the key word, and dispels fears that these repetitions may have been produced by identical key letters in different positions in the key word.
(3) When word separators have been used, the first and last letters of long polygraphic repetitions are most likely to be word separators; 26 consequently, in the case of the first repeated sequence, PTXSFIWC (representing either the second or third word of the message), Pc and Cc should represent the word separators. Now if the cipher text of the message is written out in lines of 50–60 letters or so using the repeated sequence PTXSFIWC as a sort of base, we might be able to pick out the successive word separators; this is shown in the diagram below:
IWJIRNPTXSFIWCMSDFEWSBLXQLBHFLTYIFDUVLULJRLYGHRZYIFMZXD GRMCRSWPTXSFIWCKAMWZXLXWQBAARNFLTVQAMQDZLVUQKGQZZOIHMIROLOMII XZFGPLKISCAHQZMGNWXBTIYQBDLTPNPQUDLYLGUFINSXLOHZASXAFD XTFIZPJXMMQDCPEWYIBZQGHBHRXDTXIOOLUIKVGCMGITZHWD RGGIWMYRZWNPFDCEMYFASYPJWHXJZGWWXFQXOTMCNAUUEJJIKVGHRZYIPMWID LRDCWIPGAQCSACWP
FIGURE 12
24 See the discussion on word separators in subpar. 100d of Military Cryptanalytics, Part II.
25 Occasionally, unenciphered word separators are encountered, there being employed for this purpose a character not otherwise used in the cryptographic scheme.
SEGRET
<sup>26 The occasional exceptions would be cases of the partial repetitions arising from pairs of words such as INFORMS and INFORMATION, wherein the initial letters of the ciphertext repetitions would represent a word separator, but the final letters would represent $M_p$ , the last letter of the root word.
Note that the next-to-last separator, $I_c$ , was preferred to a preceding $Z_c$ (also a possibility as a word separator) because of the final letter of the GHRZYI repetition. With the word divisions now known, it is an easy matter to make plaintext assumptions based on word lengths and idiomorphs; the rest of the solution is left to the reader as an exercise.
- (4) The foregoing example involved but a single message and a relatively short message key so that during the encryption five complete cycles of the message key were employed; it was this re-use of the keying sequence that permitted a solution. It is obvious that, regardless of the length of the key, if we had five or six messages or so in the same key, we could have written them out over one another and by careful scrutiny we could have determined the word separators much in the same fashion as was illustrated by the diagram of Fig. 12, above.
- b. The systems thus far discussed are all based upon word-length encipherment using different cipher alphabets. Words are markedly irregular in regard to this feature of their construction and thus aperiodicity is imparted to such cryptograms. But variations in the method, aimed at making the latter somewhat more secure, are possible. Instead of enciphering according to natural word lengths, the irregular groupings of the text may be regulated by other agreements. For example, suppose that the numerical value (in the normal sequence) of each key letter be used to control the number of letters enciphered by the successive cipher alphabets. Depending then upon the composition of the key word or key phrase, there would be a varying number of letters enciphered in each alphabet. If the key word were PREPARE, for instance, then the first cipher alphabet would be used for 16 (=P) letters, the second cipher alphabet, for 18 (=R) letters, and so on. Monoalphabetic encipherment would therefore allow plenty of opportunity for telltale word patterns to manifest themselves in the cipher text. Once an entering wedge is found in this manner, solution would be achieved rather rapidly.
- c. If the key of the system described in the foregoing subparagraph is short, and the message is long, periodicity will be manifested in the cryptograms, so that it would be possible to ascertain the length of the basic cycle (in this case, the length of the key) from a single message, despite the irregular groupings in encipherment. The determination of the length of the cycle might, however, present difficulties in some cases, since the basic or fundamental period would not be clearly evident because of the presence of repetitions which are not periodic in their origin. For example, suppose the word PREPARE were used as a key, each key letter being employed to encipher a number of letters corresponding to its numerical value in the normal sequence. It is clear that the length of the basic period, in terms of letters, would here be the sum of the numerical values of $P(=16) + R(=18) + E(=5) + \dots$ , totalling 79 letters. But because the key itself contains repeated letters and because encipherment by each key letter is monoalphabetic, there would be plenty of cases in which the first letter P would encipher the same or part of the same word as the second letter P, producing repetitions in the cipher text. The same would be true as regards encipherments by the two R's and the two E's in this key word. Consequently, the basic period of 79 would be distorted or masked by aperiodic repetitions, the intervals between which would not be a function of, nor bear any relation to, the length of the key. Cases are frequently encountered in which a fundamental periodicity is masked or obscured by the presence of ciphertext repetitions not attributable to a fundamental cycle; the experienced cryptanalyst is on the lookout for phenomena of this type, when he finds in a polyalphabetic cipher plenty of repetitions but with no factorable constancy which leads to the disclosure of a short period. He may conclude, then, either that the cryptosystem involves several primary periods which interact to produce a long resultant period, or that it involves a fairly long fundamental cycle within which repetitions of a nonperiodic origin are present and obscure the phenomena manifested by repetitions of periodic origin.27
- d. A logical extension of the principle of polyalphabetic encipherment of variable-length plaintext groupings is the case in which these plaintext groupings rarely exceed 4 letters, so that a given cipher alphabet is in play for only a very short time, thus breaking up what might otherwise appear as fairly long repetitions in the cipher text.
21
<sup>27 See also in this connection footnote 8 on p. 26 of Military Cryptanalytics, Part II.
-SECRE1
(1) For example, suppose that the letters of the alphabet to be used as key letters are arranged in the order of their relative frequencies in English plain text, and are set off into four groups of 5, 6, 7, and 8 letters, respectively, as follows:
ETNRO AISDLH CFPUMYG WVBXQKJZ Group 1 Group 2 Group 3 Group 4
Suppose that a key letter in Group 1 means that one letter will be enciphered; a letter in Group 2, that two letters will be enciphered; and so on. Suppose, next, that a rather lengthy phrase were used as a key; for example, I KNOW NOT WHAT COURSE OTHERS MAY TAKE BUT AS FOR ME GIVE ME LIBERTY OR GIVE ME DEATH. Suppose, finally, that each letter of the key were used to control the number of letters to be enciphered by the selected alphabet, according to the scheme outlined above. Such an enciphering scheme, using the HYDRAULIC . . . XZ primary cipher component sliding against a normal plain component, would yield the following groupings:
Grouping: Key: Ι K W Н Т C R S N 0 N 0 Т Α 0 U E Plain: TW ENTI E T HREG I M E NTHE AD QU A RTE R SNO W LO C A T ED HR PYIV S E AKYR X R Z ENAY HR SX T ZYG C WPQ Z UC G O K AR Cipher: Grouping: 1 Т F Key: ERS M Y T A K Ε В U Α S 0 R N E AR HEA DQ UAR T ER SOFF O RTYS ECO N DR EG IME N T Plain: Cipher: W I SF VQM IS TYP K CT LDQQ X HDIY BIQ C IT XH QWM A V
(2) Here it will be seen that any tendency for the formation of lengthy repetitions would be counteracted by the short groupings and quick shifting of alphabets. Before a long plaintext passage can be enciphered by exactly the same sequence of key letters, an interval of exactly 135 letters (the sum of the values of the letters in the key phrase) or a multiple thereof must intervene between the two occurrences of the plaintext passage.28 When, however, a repeated plaintext passage is at an interval of only one or two letters off from 135 or a multiple of 135, there can occur in the system under discussion a phenomenon of intermittent coincidences; i.e., coincidences not among all the ciphertext letters representing the repeated plaintext passage, but among only a few of these ciphertext letters. As an example, let us consider the following message beginnings of two messages in flush depth:
Grouping:
| 2
The word HEADQUARTERS is offset one position to the right in Message "B" with respect to its position in Message "A". (This same situation would arise if the second occurrence of HEADQUARTERS in Message "A" were at an interval of 136 letters from the first occurrence, or 271 letters, or any other multiple of 135 plus one more letter.) If we set down the cipher equivalents of the two occurrences of HEADQUARTERS under the plain text, we have the following:
H E A D Q U A R T E R S A Y H R S X T Z Y G C W A A H I S M C Z Y T V W
<sup>28 Note that, in the case of this particular key, two occurrences of a 14-letter plaintext passage could receive identical encipherments at two different positions of the key at which there are identical fragments (GIVE ME) in the key phrase; the intervals between these repeated ciphertext sequences would have nothing to do with the length of the period.
We notice that the cipher equivalents agree only in the first, third, fifth, eighth, ninth, and twelfth letters. The repetitions here extend only to one or two letters; longer repetitions can occur only exceptionally. The two encipherments yield only occasional coincidences, i.e., places where the cipher letters are identical; moreover, the distribution of the coincidences is quite irregular and of an intermittent character. This phenomenon of intermittent coincidences, involving coincidences of single letters, pairs of letters, or short sequences (rarely ever exceeding pentagraphs) is one of the characteristics of this general class of polyalphabetic substitution, wherein the cryptograms commonly manifest what appears to be disturbed or distorted periodicity.
e. As has already been noted, in aperiodic systems wherein the key is determined or generated apart from the plain text being enciphered (as is the case of the example in the foregoing subparagraph), cryptographic depth is possible; therefore the analyst may be able, if keying conditions permit, to superimpose messages and solve the resultant superimposition. On the other hand, in systems wherein the plain or cipher text influences or governs in any way the selection of keys, cryptographic depth is usually impossible of establishment, except in very special circumstances.
f. The essence of the systems described in this chapter really comprises monoalphabetic substitution in irregular, and usually small, segments; nevertheless, these segments were large enough to permit of their isolation and exploitation. As the size of these segments decreases, ultimately to units of single letters, so does the difficulty of solution increase—but not beyond the potentials of cryptanalysis, as will shortly be demonstrated.
1
CHAPTER III
SYSTEMS USING VARIABLE-LENGTH KEYING UNITS TO ENCIPHER CONSTANT-LENGTH PLAINTEXT GROUPINGS
| Paragraph | |
|---|---|
| General | 14 |
| Plaintext interruptor systems | 15 |
| Ciphertext interruptor systems | 16 |
| Systems empl~ying externally generated or determined keys | 17 |
| Solution when known cipher alphabets are employed | 18 |
| Solution when unknown cipher alphabets are employed | 19 |
| Additional remarks | 20 |
- 14. General.-a. The systems treated in the preceding chapter incorporated simple methods of eliminating or avoiding periodicity by enciphering variable-length groupings of the plain text, using constant-length keying units; the essence of those systems was really monoalphabetic encipherment by sections,1 the sections comprising irregular-length plaintext groupings. In subpar. 2a, however, it was pointed out that periodicity can also be suppressed by applying variable-length keying units to constantlength plain text groupings; the essence of such systems is poly alphabetic substitution applied to the plaintext units (usually single letters). One such method consists in irregularly interrupting the keying sequence, if the latter is of a limited or fixed length, and recommencing it (from its initial point) after such interruption, so that the keying sequence becomes equivalent to a series of keys of different lengths. Thus, the key phrase BUSINESS MACHINES might be expanded, by a particular keying convention, into a series of irregular-length keying sequences, such as BUSI/BUSINE/BU/BUSINESSM/BUSINESSMAC, etc. Various schemes or prearrangements for determining the type or character of the interruptions may be adopted. Several typical methods will now be described.
- b. There are many methods of interrupting a keying sequence which is basically cyclic and which therefore would give rise to periodicity if not interferred with in some way. These methods may, however, be classified into six general cases as regards what happens after the interruption occurs.2
- Case I: The keying sequence merely stops and begins again at the initial point of the cycle.
- Case II: Certain elements of the keying sequence may "stutter" or be repeated a fixed or a variable number of times.
- Case III: One or more of the elements in the keying sequence may be omitted from time to time irregularly.
- Case IV: The keying sequence irregularly alternates in its direction of progression.3
- Case V: The keying sequence irregularly alternates in its direction of progression, and, in addition, certain elements of the keying sequence may be repeated one or more times.
- Case VI: The keying sequence irregularly alternates in its direction ~f progression, and, in addition, one or more of the elements in the keying sequence are omitted from time to time irregularly.
- c. The foregoing methods may, for clarity, be represented graphically as follows. Suppose the key consists of a cyclic seqQence of 10 elements represented symbolically by the series of numbers 1, 2, 3, . 0. Indicating an interruption by a vertical line/ we show in Fig. 13, below, the relationship between
25 ..SiGAH
1 See in this connect.ion subpar. 84b(l) on p. 220 of Military Cryplanalytics, Part I.
2In addition to the:-:e cases, a "septimum quid" could be listed, as a catchall for "everything else," which includes progressions so irregular as to defy classification.
**J**It is to be noted that this fourth case could be treated as though it were a special form (with irregularly occurring small or large skips) of the third case.
' What specifically brings about the interruption is here not stated, nor for that matter does it concern us at the moment. Suffice it to say that, whatever the cause of the interruption, it is not a function of the plain or of the cipher text, but is in this case predetermined by an external convention with steps 3, 1, 6, 7, 5, 8, 2, 4, 9 .
the letter at each position of the message and the identity of the element of the keying sequence in the six general cases discussed above.
Letter No. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Key elements, Case I: 1 2 3 1 1 2 3 4 5 6 1 2 3 4 5 6 7 1 2 3 4 5 1 2 3
Key elements, Case II: 1 2 3 3 3 4 5 6 7 8 8 9 0 1 2 3 4 4 5 6 7 8 8 9 0
Key elements, Case III: 1 2 3 5 7 8 9 0 1 2 4 5 6 7 8 9 0 2 3 4 5 6 8 9 0
Key elements, Case IV: 1 2 3 2 3 4 5 6 7 8 7 6 5 4 3 2 1 2 3 4 5 6 5 4 3
Key elements, Case V: 1 2 3 3 3 4 5 6 7 8 8 7 6 5 4 3 2 2 3 4 5 6 6 5 4
Key elements, Case VI: 1 2 3 5 7 8 9 0 1 2 4 3 2 1 0 9 8 0 1 2 3 4 6 5 4
Letter No.
Key elements, Case I:
Key elements, Case II:
Key elements, Case III:
Key elements, Case IV:
Key elements, Case V:
Key elements, Case VI:
26 21 2~ 29 ao a1 32 33 34 35 36 37 as 39 40 41 42 43 44 45 46 47 48 40 sll
4 5 6 7 8 1 2 1 2 3 4 1 2 3 4 5 6 7 8 9 1 2 3 4 5
1 2 3 4 5 5 6 6 7 8 9 9 0 1 2 3 4 5 6 7 7 8 9 0 1
1 2 3 4 5 7 8 0 1 2 3 5 6 7 8 9 0 1 2 3 5 6 7 8 9
2 1 0 9 8 9 0 9 8 7 6 7 8 9 0 1 2 3 4 5 4 3 2 1 0
3 2 1 0 9 9 0 0 9 8 7 7 8 9 0 1 2 3 4 5 5 4 3 2 1
3 2 1 0 9 1 2 4 3 2 1 3 4 5 6 7 8 9 0 1 3 2 1 0 9
FIGURE 13
Note that in Cases III and VI the amount of skip is here portrayed as being constant. This is not a necessary condition in these keying methods; the amount of skip could have consisted of irregular jumps as established by the keying convention employed.
d. If we knew just when the interruptions take place, and if we also knew the exact nature of the effect of each interruption, 5then the successive ciphertext sections of encrypted messages in the foregoing six cases could be properly superimposed so as to be in true cryptographic depth. In the diagrams below, the digits in the top line represent the ten keying elements, while the numbers 1-50 underneath this line represent the positional identities of the first 50 ciphertext letters.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| (1 | 2 | 3) | ||||||||
| ( 4) | ||||||||||
| (5 | 6 | 7 | 8 | 9 | 10) | |||||
| ( 11 | 12 | 13 | 14 | 15 | 16 | 17) | ||||
| (18 | 19 | 20 | 21 | 22) | ||||||
| Case I | (23 | 24 | 25 | 26 | 27 | 28 | 29 | 30) | ||
| (31 | 32) | |||||||||
| (33 | 34 | 35 | 36) | |||||||
| (37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45) | ||
| (46 | 47 | 48 | 50 | |||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| (1 | 2 | 3) | ||||||||
| ( 4) | ||||||||||
| (5 | 6 | 7 | 8 | 9 | 10) | |||||
| 15 | 16 | 17) | ( 11 | 12 | 13- | |||||
| (18 | 19 | 20 | 21 | 22) | ||||||
| Case II | 27 | 28 | 29 | 30) | (23 | 24 | 25- | |||
| (31 | 32) | |||||||||
| (33 | 34 | 35 | 36) | |||||||
| 40 | 41 | 42 | 43 | 44 | 45) (46 |
47 | (37 48 |
5These two points could have been determined either through physical compromise of a cipher machine incorporating such principles, or through the analytical compromise of a cryptosystem.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Ø | |
|---|---|---|---|---|---|---|---|---|---|---|
| (1 | 2 | 3) | (4) | (5 | 6 | 7 | 8→ | |||
| → `9 | 10) | (11 | 12 | 14 | 15 | 16 | 17) | |||
| Case III | (18 | 19 | • | 21 | 22) | (23 | 24 | 25→ | ||
| →26 | 27 | 28 | 29 | 30) | • | (31 | 32) | (33→ | ||
| →34 | 35 | 36) | (37 | 38 | 39 | 40 | 41 | 42→ | ||
| →43 | 44 | 45) | (46 | 47 | 48 | 49 | 50 | |||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ø | |
| (1 | 2 | 3) | ||||||||
| • | (4) | (5 | 6 | 7 | 8 | 9 | 10) | |||
| (17 | Ì6 | Ì5 | 14 | 13 | 12 | - | ||||
| • | (18 | 19 | 20 | 21 | 22) | |||||
| Case IV | ←27 | 26 | 25 | 24 | 23) | - | (30 | 29 | 28← | |
| • | • | (31 | ||||||||
| (36 | 35 | 34 | 33) | |||||||
| →41 | 42 | 43 | 44 | 45) | • | 3 8 | 49 | |||
| ←4 9 | 48 | 47 | 46) | - | ||||||
| - | ||||||||||
| _1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ø | |
| (1 | 2 | 3) | : | · | ||||||
| (4) | ||||||||||
| (5 | 6 | 7 | 8 | 9 | 10) | |||||
| (17 | 16 | 15 | 14 | 13 | 12 | 11) | ||||
| (18 | 19 | 20 | 21 | 22) | · | |||||
| $\mathbf{Case};\mathbf{V}$ | ←28 | 27 | 26 | 25 | 24 | 23) | (30 | 29← | ||
| , | (31 | 32) | ||||||||
| (36 | 35 | 34 | 33) | |||||||
| →41 | 42 | 43 | 44 | 4 5) | (37 | 38 | 39 | 40→ | ||
| . 50 | 49 | 48 | 47 | 4 6) | - | |||||
| • | ||||||||||
| _1 | 2 | 3 | 4 | 5 (4) |
6 | 7 | 8 | 9 | ø | |
| (1 | 2 | 3) | $\overline{(4)}$ | |||||||
| → 9 | 10) | • | (5 | 7 | 8→ | |||||
| ←14 | 13 | 12 | 11) | ı | (17 | 16 | 15← | |||
| →19 | 20 | 21 | 22) | (18→ | ||||||
| Case VI | ←28 | 27 | 26 | 25 | 24 | 23) | (30 | 29← | ||
| (31 | 32) | |||||||||
| (36 | 3 5 | 34 | 33) | |||||||
| →4 5 | ) | (37 | 3 8 | 3 9 | 40 | 41 | 42 | 43 | 44→ | |
| ←4 8 | 47 | 46) | 50 | 49← | ||||||
Obviously, if we did not know when or how the interruptions take place, then the successive sections of keying elements cannot be superimposed as indicated above.
e. The interruption of the fundamental cyclic keying sequence usually takes place according to some prearranged plan or convention. The identity of the plaintext letters being enciphered might be involved in the determination of the interruption (as in plaintext interruptor systems); 6 or the identity of the ciphertext letters might be a factor (as in ciphertext interruptor systems); or, finally, the interruption of the fundamental cyclic keying sequence might be predicated upon a separate convention,
<sup>6 In the Wheatstone cipher device the interruption of the keying sequence of the 26 cipher alphabets used in sequential progression is predicated upon the relative position in the plain component of a plaintext letter with respect to the position (in the plain component) occupied by the next plaintext letter to be encrypted. (See Chapter VIII in this connection.)
mechanism, or prearrangement, without regard to the plain text or the cipher text. Some basic methods of interruption will now be taken up, using a short mnemonic key as an example.
- Plaintext interruptor systems.—a. Suppose the correspondents agree that the interruption in the key will take place after the occurrence of a specified letter in the plain text, after which the key begins anew at its initial position. Since there is nothing fixed about the time the interruption will occur—it will take place at no fixed intervals—not only does the interruption become quite irregular, following no pattern, but also the method never reverts to one having periodicity. Let us assume that the correspondents have agreed upon Rp as the interruptor letter, and that they are using the normal sequence for the plain component and the HYDRAULIC . . . XZ sequence for the cipher component. If the mnemonic key phrase is BUSINESS MACHINES, this key would be interrupted by the occurrences of Rp as in the following example:
Key: BUSINESSMACHIBUSBUSIBUSINE Plain: AMMUNITIONFORFIRSTARTILLER Cipher: BOLYRPJDROJKXKJFYXSXDJUPSY
Key: BUSINESSMACHINESBUBUSINESSMACHI Plain: YWILLBELOADEDAFTERAMMUNITIONFOR Cipher: IYDPYFXURAFAENMJJVBOLYRPJDROJKX
Key: BUSIBUSBUSINEBUSIN Plain: THIRDARTILLERYSTOP... Cipher: DGDXGUFDJUPSYIWJTU
The final cipher text, in groups of five letters, would be the following:
BOLYR PJDRO JKX KJ FYXSX DJUPS YIYDP YFXUR AFAEN MJJVB OLYRP JDROJ KXDGD XGUFD JUPSY IWJTU...
It will be noted that the two long polygraphic repetitions are at intervals of 44 and 34, respectively, which intervals have nothing in common with 16, the length of the basic, uninterrupted period.
b. Instead of employing an ordinary plaintext letter as the interruptor letter, one might use a 25-letter plain component, combining I with J, and then use the 26th character (J) as a null plaintext letter which is inserted at random by the encipherer to serve as the interruptor letter. Note the following example:
Key: BUSINESSMABUSINESSMACHINESBUSBUSIN Plain: PROCEEDTOJROADIUNCTIONSIXTWOJFIVEJ...
c. It is obvious that repetitions would be plentiful in cryptograms of this construction, regardless of whether a letter of high-, medium-, or low-frequency is selected as the signal for key interruption. If a letter of high frequency is chosen, repetitions will occur quite often, not only because that letter will certainly be a part of many common words, but also because it will be followed by words that are frequently repeated; and since the key starts again with each such interruption, these frequently repeated words will be enciphered by the same sequence of cipher alphabets. This is the case in the first of the two foregoing examples. It is clear, for instance, that every time the word ARTILLERY appears in the cryptogram the cipher equivalents of TILLERY must be the same. If the interruptor letters were Ap instead of Rp, the repetition would include the cipher equivalents of RTILLERY; if it were Tp, ILLERY, and so on. On the other hand, if a letter of very low frequency were selected as the interruptor letter, then the encipherment would tend to approximate that of normal periodic substitution, and repetitions would be plentiful on that basis alone. Of course, the intervals between the repetitions in any of the
<sup>7 This is Case I of subpar. 14b.
~~egoing cases (except perhaps that in which the plaintext interruptor is a letter of very low frequency) .:ould be markedly irregular, so that periodicity would not be manifested.
16. Ciphertext interruptor. systems.-a. In the systems of the preceding paragraph, a plaintext let.ter serves as the interruptor letter. But now suppose the correspondents agree that the interruption _- in the key will take place immediately after a previously agreed-upon letter, say Q., occurs in the cipher text. The key would then be interrupted as shown in the following example:
Key: B U S I N E S S M A C H I N E S B U S I N E S S M Pl~n: AM MUN IT ION FOR FIRST ART ILLE Cipher: B O L Y R P J D R O J K X T P F Y X S X B P U U Q
Key: B U S I N E S S M A C H I N B U S I N E S S M A C H B U Plain: RY WILL BELO ADE DAFTER AM MUN IT I 0 Cipher: H R N M Y T T X H P C R F Q B E J F I E L L B O N Q O Q
Key: B U S I N E S S M A C H B U S I N E S S M A Plain: N F O R T H I R D A R T I L L E R Y S T O P Cipher: V E C X B O D F P A Z Q O N U F I C G J R Q
The cipher text in 5-letter groups is as follows:
B O L Y R P J D R 0 T T X H P C R F Q B F P A Z .Q..._Q N U F I J K X T P E J E._LE CG JR Q Fy X sL~ p u u Q L L B O N Q__Q Q V E HR NM Y C X B O D
b. In the foregoing example, there are no significant repetitions; such as do occur comprise only digraphs, several of which are purely accidental. But the absence of significant, long repetitions is itself purely accidental, for had the interruptor letter been a letter other than Q., then the phrase AMMUNITION FOR (which occurs twice) might have been enciphered identically both times. If a short key is employed, repetitions may be plentiful. For example, note the following, in which S0 is the interruptor letter: 8
Key: B A N D S B A N D S B A N D S B A N D S B A N B A N D S B B A Plain: FROM FOUR FIVE TO FOUR F _IF TEEN WILL BE Cipher: K T A K Z W X I I D A C B N Z W X I I D K W S J O G E U S E C
- c. This last example gives a clue to one method of attacking this type of system. There will be repetitions within short sections, and the interval between them will sometimes permit ascertaining the length of the basic key. In such short sections, the letters which intervene between the repeated sequences may be eliminated as possible interruptor letters. Thus, in the foregoing example, we can deduce that the length of the basic key is 5 letters, and that the cipher letters A, C, B, and N may be eliminated as interruptor letters. By extension of this principle to the letters intervening between other repetitions, one may more-or-less quickly ascertain what ciphertext letter serves as the interruptor. 9
- d. The ciphertext interruptor might be a letter which is not otherwise used in the cryptographic scheme; for example, the plain component might be a 25-letter sequence (combining I and J) and the cipher component a 25-letter sequence excluding, let us say, Z. This letter Z may then be inserted in appropriate places in the cipher text to signal the interruptions in the keying cycle. In some cases such a special interruptor letter may be used in addition to a ciphertext interruptor which arises from the bona fide encryption of a plaintext letter, as a means of insuring that interruption of the keying cycle will take place frequently enough to suit the cryptographer or his procedures-prescribing superiors.
8 Note that the periodic repetitive phenomena manifested would also have arisen in a plaintext interruptor system, if the interruptor had been, let us say, Ap-or, for that matter, any other letter not present in the fragment FOURFI VETOFOURFI. . .
' The method described in this subparagraph may also be applied in the case of plaintext interruptor systems, with certain modifications.
SECRET
(For that matter, there is nothing to bar the use of two or more letters as interruptors in the usual manner, in either plaintext interruptor or ciphertext interruptor systems.)
- Systems employing externally generated or determined keys.—a. In subpars. 3b and f we have seen two examples of keying procedures which do not depend upon conventions affiliated with identities of plaintext or ciphertext letters, but which are established by an independent, external keying convention. The keying methods of subpar. 3b, if modified to incorporate variable-length polyalphabetic keying units (as contrasted with the variable-length monoalphabetic keying units illustrated in that example), could take on a form such as the following:
| _ | NALSI 12 34 5 |
||||||||
|---|---|---|---|---|---|---|---|---|---|
| SIGNA 12345 |
|||||||||
| _ | ALSIG |
etc. |
Similarly, the keying method of subpar. 3f, modified to embrace the aspect of variable-length polyalphabetic keying units, could be transformed into one of the following, among other possibilities:
- (1) D E F/E/C D E F/L M N O/A B/R S T/A B/T/I J/O P Q/N O/O P Q/F G H I/. . .
- (2) D E C/E/C L A R/L A R A/A R/R A T/A T/T/I O/O N O/N O/O F I/F I N D/. . .
- b. The foregoing methods have as their purpose the establishment of keys of fair length from a short mnemonic key. There are other simple methods for accomplishing this, as illustrated in the examples which follow. Let us consider the mnemonic key HYDRAULIC, and derive from it a numerical key:
H Y D R A U L I C
We may now take the key letters in numerical-key order, and in groupings as determined by the numerical key, so that the original key of only 9 letters is expanded to one of 45 letters. Thus:
(1) A/C H/D R A/H Y D R/I C H Y D/L I C H Y D/R A U L I C H/U L I C H Y D R/Y D R A U L I C H/
Two other methods of deriving 45-element key sequences from the basic 9-letter key word are shown below:
- (2) H Y D R/Y D R A U L I C H/D R A/R A U L I C H/A/ U L I C H Y D R/L I C H Y D/I C H Y D/C H/
- (3) HYDRA/HYDRAULIC/HYD/H/HYDRAULI/ HYDRAUL/HYDR/HYDRAU/HY/
Method (2) is essentially the same as (1), except that the key fragments are taken in the order in which they appear in the key word. Method (3) involves taking the successive sections of the numerical key, these sections terminating with the successive numbers 1, 2, 3, . . . of the numerical key.10
- c. Many other methods exist for the establishment of keys consisting of variable-length keying units. Furthermore, some of these methods merge into the domain of methods of lengthening or extending keys in general, apart from any considerations of variable-length keying units. Several of the most important of these methods will be discussed in subsequent chapters of this text.
- Solution when known cipher alphabets are employed.—a. (1) Let us suppose that a particular cryptosystem has been in use for some time, and that the general nature of the system and the cipher
<sup>10 This method is equivalent to an interrupted-key columnar transposition system. See in this connection subpar. 51h on p. 89 of Military Cryptanalytics, Part I.
alphabets have become known, either through successful cryptanalysis or through light-fingered techniques coming under the formal term of "physical compromise," which includes among its manifold tachydactylurgic aspects that which has been referred to colloquially as "wastebasket cryptanalysis." 11 Only the specific key to messages remains unknown. The cipher text is examined for repetitions, and an attack is made on the basis of searching for a probable word. Thus, taking the cryptogram in subpar. 15a as an example (quoted here below for convenience), suppose the presence of the word ARTILLERY is suspected.
BOLYR PJDRO JKXKJ FYXSX DJUPS YIYDP XFXUR AFAEN MJJVB OLYRP JDROJ KXDGD XGUFD JUPSY IWJTU...
Attempts are made to locate this word, basing the search upon the recognition of an intelligible key; we will assume in this case that the cipher component is the HYDRAULIC . . . XZ sequence sliding against the normal sequence for the plain component.
(2) Beginning with the very first letter of the message, we juxtapose the word ARTILLERY against the cipher text and ascertain the key letters. Thus:
Key: B·H J Q P I B F U Cipher: B O L Y R P J D R Plain: A R T I L L E R Y
Since this "key" is certainly not intelligible text, the assumed word is moved one letter to the right and the test repeated, and so on until the 19th position in the text is reached.12
Key: SIBUSINEB Cipher: SXDJUPSYI Plain: ARTILLERY
(3) The sequence BUSINE suggests BUSINESS; moreover, it is noted that the key appears to be interrupted both times by the letter $R_p$ . The key may now be applied to the beginning of the message, to see whether the whole key or only a portion of it has been recovered. Thus:
Key: BUSINESSBUSINES Cipher: BOLYRPJDROJKXKJ... Plain: AMMUNITIUMTHIET
(4) It is obvious that BUSINESS is only a part of the key. But the first word of the message is plainly AMMUNITION. When this is tried, the key is extended to BUSINESS MA... This key crib is now slid through the rest of the cipher text and the remainder of the message is quickly deciphered and the entire key recovered.
<sup>13 In actual practice, the search for the placement of the probable word would have been accomplished by means of the following diagram (see in this connection subpar. 22d on pp. 41-42 of Military Cryptanalytics, Part II):
| В | 0 | L | Y | R | P | J | D | R | 0 | J | K | x | K | J | F | Y | x | s | X | D | J | บ | P | s | Y | I | Y | D | P | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | В | 0 | L | Y | R | P | J | D | R | 0 | J | K | X | K | J | F | Y | X | Ş | X | D | J | U | P | S | Y | Ī | Y | D | P | |
| R | ĺ | Н | W | ||||||||||||||||||||||||||||
| T | J | C | E | Z | S | В | Е | X | S | T | U | T | S | P | C | U | Y | ŋ | √B | S | G | Z | Y | C | K | С | В | Z | |||
| I | Q | L | |||||||||||||||||||||||||||||
| L | P | I | D | 0 | P | L | D | R | J | R | D | Н | N | J | В | J | 0 | D | Ş | I | В | N | V | N | 0 | I | |||||
| L | I | D | 0 | P | L | D | R | J | R | D | Н | N | J | В | J | 0 | D | 3 | Į | В | N | V | N | 0 | I | ||||||
| E | _ | Ŋ | |||||||||||||||||||||||||||||
| R | \ | Æ | |||||||||||||||||||||||||||||
| Y | \ | ₽ | |||||||||||||||||||||||||||||
<sup>11 This is really not stealing. For the pure in heart, this should be thought of as conversion of raw data, and that the parties so generously supplying these raw data are, unknowingly, cooperating in government work.
(b) (1) (b) (3) -18 USC 798 (b) (3) -50 USC 3024(i) (b) (3) -P.L. 86-36
| -CECRET. |
|---|
(b) (1)
(b) (3) -18 USC 798
(b) (3) -50 USC 3024(i)
(b) (3) - P.L. 86 - 36
d. (1) Another technique, if we know or can assume the method of key interruption (e.g., a skip over one element of the key after the occurrence of a previously designated ciphertext letter, in this case Wc), involves writing out the modified cipher text of a single message on trial widths in order to see if any cyclic properties are present in the basic, uninterrupted key. We can then determine statistically when the correct cyclic write-out is reached by the application of a technique discussed in the preceding text.16 As an example, let us assume the following message is at hand:
GSWWT
RHZDW
GLNUJ
WXRWR
HNQLS
YXTEV
GCVBW
CWZUV
IAVFG
XXFNP
HGPHA
MIKDR
VCTEA
VCAWG
JICGG
CISNS
IVCJB
SZSRW
VLKZR
JBHCC
WJMRL
WTLRS
CAYQV
DJXFN
ZZIAF
MQJCX
(2) If we know the method of interruption and also the identity of the ciphertext interruptor, 17 we would write out the appropriately modified cipher text on various widths, testing each hypothesis in turn, until a satisfactory I.C. is reached for an entire columnar array. For example, if we know that the enemy is using key words and phrases from 11 to 40 letters in length as the basic key sequence, we would begin by writing out the modified cipher text (on the assumption of $W_c$ as the interruptor letter) on a width of 11 as shown below, together with the appropriate $\phi$ values for the computations:
1 2 3 4 5 6 7 8 9 10 11
G S W . W . T R H Z D
W . G L N U J W . X R
W . R H N Q L S Y X T
E V G C V B W . C W .
Z U V I A V F G X X F
N P H G P H A M I K D
R V C T E A V C A W .
G J I C G G C I S N S
I V C J B S Z S R W .
V L K Z R J B H C C C
A Y Q V W . J M R L W
. T L R S D J X F N Z
Z I A F M Q J C X
$\frac{\phi}{\phi}$ 16 6 6 4 2 4 2 13 11 13 12 12 16 6 6 14 2 $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi}{2}$ $\frac{\phi
(b)(1)
(b)(3)-18 USC 798
(b) (3) - 50 USC 3024(i)
(b) (3) - P.L. 86 - 36
(3) The row of numbers immediately beneath the write-out represents the $\phi$ values of the columns; the row beneath the " $\phi$ " row, labelled "N", represents the number of letters in the columns. Since there
<sup>16 Cf. Subpar. 18e on pp. 28-31 of Military Cryptanalytics, Part II.
<sup>17 If worst came to worst, we could test each of the 26 letters in turn as the ciphertext interruptor. This testing, coupled with the writing out of the cipher text on the various widths, would be quite laborious and time-consuming by manual methods; data processing machine techniques would here be very useful.
are 3 columns of 13 letters each, 5 columns of 12 letters each, 2 columns of 11 letters, and 1 column of 9 letters, the expected value of $\phi$ random ( $\phi_r$ ) is given by the formula
$$\phi_{r} = \frac{3(13\cdot12) + 5(12\cdot11) + 2(11\cdot10) + 1(9\cdot8)}{26} = \frac{1420}{26} = 54.6$$
The $\delta$ I.C. is defined as the ratio of the observed value of $\phi$ to the expected value of $\phi$ random, or $\frac{\phi_0}{\phi_r}$ . Now since the $\phi_0$ (which is the sum of all the $\phi$ values for the columns) is 64, our I.C. formula becomes, by simple algebraic transformation,
$$\delta I.C. = \frac{26.64}{3(13.12) + 5(12.11) + 2(11.10) + 1(9.8)} = \frac{1664}{1420} = 1.17$$
(4) This I.C. of 1.17 is not satisfactory, so we continue testing successively greater widths, until the width of 32 is reached:
$$\begin{array}{cccccccccccccccccccccccccccccccccccc$$
At this width, the I.C. calculation becomes
$$\delta I.C. = \frac{26.30}{7(5.4) + 21(4.3) + 3(3.2) + 1(2.1)} = \frac{780}{412} = 1.89,$$
giving statistical credence to the assumption of 32 as the correct width, since we were looking for an I.C. in the vicinity of 1.73 for the correct case. 18 Knowing the components involved, we may complete the plain-component sequence on the letters of the columns to effect a speedy solution.
- Solution when unknown cipher alphabets are employed.—a. In the first text in this series, it was pointed out that "in the final analysis, the solution of every cryptogram involving a form of substitution depends upon its reduction to monoalphabetic terms, if it is not originally in those terms." 19 In the preceding volume, it was observed that when in the course of solution of an ordinary repeating-key cipher the text is written out in period-lengths, "another way of looking at the matter is to conceive of the text as having thus been transcribed into superimposed periods; in such a case the letters in each
18 The reader might be interested in the I.C.'s for all the widths from 11 to 40; these are shown in the following table:
| w | δ | w | δ | w | δ | w | δ | w | δ | w | δ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 12 13 |
1. 17 1. 09 1. 06 0. 91 |
16 17 18 19 |
1. 11 0. 95 1. 03 1. 02 |
21 22 23 24 |
0. 91 1. 35 1. 18 1. 17 |
26 27 28 29 |
1. 06 1. 24 0. 98 1. 67 |
31 32 33 34 |
1. 08 1. 89 0. 79 0. 68 |
36 37 38 39 |
1. 33 1. 69 1. 28 0. 98 |
| 15 | 1. 29 | 20 | 0. 86 | 25 | 1. 20 | 30 | 1. 29 | 35 | 1. 14 | 40 | 1. 01 |
Note the I.C. of 1.67 for the width of 29, and the I.C. of 1.69 for the width of 37. These I.C.'s are certainly satisfactory; however, the widths from which they were derived are incorrect, so that they represent the vagaries of the touch not of a Mephistophelian finger, but rather that of a Bernoullian digit when an insufficient number of trials is involved.
19 Military Cryptanalytics, Part 1, subpar. 17b.
SECRET
column have undergone the same kind of treatment by the same elements (plain and cipher components of the cipher alphabet)." 20 It follows that, even if the repeating key is very long, if there are many short cryptograms all enciphered by exactly the same key and each message begins at the same point in the key, the distributions applicable to the successive columns of text can be solved. 21 Even in aperiodic systems, if there is available a number of messages starting out in the same key which then diverges in the course of encipherment according to the nature of the cryptosystem, this solution by superimposition may be applicable in particular cases, so long as the key divergence is not too radical for cryptanalytic comfort.
b. Let us study the following beginnings of 30 messages, passed between correspondents known to have used various types of aperiodic keying:
| 5 | 10 | 15 | 5 | 10 | 15 | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. | Y | F | W | F | M | R | I | Q | M | X | X | E | L | M | J | 16. | G | 0 | Е | Q | В | Q | 0 | T | L | E | S | A | C | R | В | |||
| 2. | Н | W | ₩ | T | T | E | C | T | D | 0 | Z | F | D | 0 | v | 17. | W | T | S | R | G | X | M | Z | T | V | S | J | Q | L | X | |||
| 3. | T | P | Y | F | K | S | 0 | V | W | Ι | Н | F | N | C | J | 18. | W | T | E | ٧ | F | C | Ι | В | T | S | P | R | C | A | T | |||
| 4. | Y | P | E | P | S | N | L | S | K | Z | N | V | T | J | В | 19. | Z | C | V | Y | M | В | V | N | Y | W | Q | U | Z | G | U | |||
| 5. | E | A | Q | U | Z | D | V | E | S | K | C | Ι | U | P | A | 20. | Z | C | T | T | Z | W | C | T | T | I | K | H | Q | U | T | |||
| 6. | Z | C | G | M | W | T | N | В | I | M | K | U | S | N | L | 21. | Z | C | C | T | S | N | E | S | K | 0 | U | В | M | P | T | |||
| 7. | Е | P | D | 0 | Z | F | D | 0 | v | В | I | L | V | L | W | 22. | A | F | E | S | J | 0 | N | K | T | D | V | E | S | K | C | |||
| 8. | E | P | T | L | E | _S | A | C | R | В | M | P | T | P | J | 23. | Z | C | F | F | D | T | N | P | F | D | Н | D | T | P | F | |||
| 9. | W | M | L | S | 0 | T | 0 | Z | E | E | J | Z | G | V | K | 24. | V | Z | Ι | E | X | R | X | R | F | F | U | N | T | Q | E | |||
| 10. | Z _ | C | F | F | D | C | F | R | J | W | Н | L | P | D | T | 25. | E | P | S | N | L | S | K | L | 0 | Н | W | P | T | R | G | |||
| 11. | H | C | Q | E | D | T | P | Y | I | L | N | R | E | M | ٧ | 26. | Y | T | S | V | W | L | S | T | L | E | S | A | C | R | B | |||
| 12. | C | L | C | T | Z | I | K | S | 0 | E | 0 | Z | C | T | T | 27. | W | A | $\mathbf{Z}$ | X | Z | Q | A | C | H | Q | U | T | L | S | T | |||
| 13. | H | C | Q | E | F | D | K | I | F | Q | W | 0 | C | L | M | 28. | N | 0 | F | T | Z | N | L | H | Q | U | T | J | Н | Z | A | |||
| 14. | E | P | T | W | K | S | U | $\mathbf{z}$ | N | V | V | A | U | C | S | 29. | V | R | C | W | K | M | 0 | L | N | X | W | S | D | 0 | L | |||
| 15. | Z | A | В | M | Z | Н | G | 0 | F | X | Q | I | G | M | M | 3 0. | S | P | R | C | P | F | X | E | 0 | J | C | Q | F | W | M |
<sup>20 Military Cryptanalytics, Part II, subpar. 65a.
<sup>21 Cf. subpar. 65b, Military Cryptanalytics, Part II.
The presence of digraphic and polygraphic repetitions in the initial columns could mean that the messages start out in flush depth, and the presence of offset repetitions could be an indication of shifts in the keying sequence. Frequency distributions for the columns are made and are shown in Fig. 16, below, accompanied by their I.C.'s:
- ABCDEFGHIJKLMNOPQRSTUVWXYZ 2. ABCDEFGHIJKLMNÖPQRSTUVWXYZ 3. ABCDEFGHIJKLMNOPQRSTUVWXYZ 4. ABCDĒFGHIJKLMNOPQRSTŪVWXYZ 5. ABCDEFGHIJKLMNOPQRSTUVWXYZ 6. ABĈDEFGHIJKLMNOPQRSTUVWXYZ 7. $\overrightarrow{A}$ B $\overrightarrow{C}$ $\overrightarrow{D}$ $\overrightarrow{E}$ $\overrightarrow{F}$ $\overrightarrow{G}$ H $\overrightarrow{I}$ J $\overrightarrow{K}$ L $\overrightarrow{M}$ $\overrightarrow{N}$ $\overrightarrow{O}$ P Q R $\overrightarrow{S}$ T $\overrightarrow{U}$ $\overrightarrow{V}$ $\overrightarrow{W}$ $\overrightarrow{X}$ Y Z 8. ABCDEFGHIJKLMNOPQRSTUVWXYZ 9. A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 10. ABCDEFGHIJKLMNÖPQRSTUVWXYZ 11. ABCDEFGHIJKLMNOPQRSTUVWXYZ-1.02 12. ABCDEFGHIJKLMNOPQRSTUVWXYZ 13. ABĈDEFGHIJKLMNOPQRSTÜVWXYZ 14. ÂBĈDEFGHIJKLMNÖPQRSTUVWXYZ 15. $\vec{A}$ $\vec{B}$ $\vec{C}$ $\vec{D}$ $\vec{E}$ $\vec{F}$ $\vec{G}$ $\vec{H}$ $\vec{J}$ $\vec{K}$ $\vec{L}$ $\vec{M}$ $\vec{N}$ $\vec{O}$ $\vec{P}$ $\vec{Q}$ $\vec{R}$ $\vec{S}$ $\vec{T}$ $\vec{U}$ $\vec{V}$ $\vec{W}$ $\vec{X}$ $\vec{Y}$ $\vec{Z}$ FIGURE 16
- c. The first two columns are certainly monoalphabetic; after that, there is a rapid falling off in monoalphabeticity, with the exceptions of cols. 5, 13 and 15 which could be due to chance. We note the digraph ZCc which occurs 6 times in cols. 1 and 2; this could well be the equivalent of REp, and HCc in cols. 1 and 2 could stand for SEp. On this basis, ZCFFD in Messages 10 and 23 could represent REFER, and HCQE in Messages 11 and 13 could be SEND. We then note
- Z C F F D T N P F D H D T P F . . . . R E F E R
- Z C G M W T N B I M K U S N L . . . R E
SEGRET
which could represent REFERENCE and REGIMENT. We now turn our attention to the following four message beginnings:
If we assume that $T_c$ in col. 4 represents $O_p$ , then in No. 28—FOR . . . becomes INFORM(ATION), in No. 20 RE-OR- becomes REPORT, in No. 21 RE-O . . . becomes RECOMMEND, and in No. 12—COR--N-becomes ACCORDING.
d. The plain-cipher equivalencies from the foregoing assumptions are entered into a sequence reconstruction matrix, as shown below:
| A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | C | N | Z | Н | • | |||||||||||||||||||||
| 2 | L | C | 0 | |||||||||||||||||||||||
| 3 | C | _ | F | G | _ | Q | T | |||||||||||||||||||
| 4 | E) | F | ( | (M) | ) | |||||||||||||||||||||
| 5 | w 8 | $\mathbf{p}_{\mathbf{z}}$ | ||||||||||||||||||||||||
| 6 | Ι | T | N | W | ||||||||||||||||||||||
| 7 | L | E | K | N | , | |||||||||||||||||||||
| 8 | P | _ | _ | S | В́н | |||||||||||||||||||||
| 9 | ( | (K) | F | 0 | ( | (Q) | ) | Í | ||||||||||||||||||
| 10 | U | |||||||||||||||||||||||||
| 11 | , | T |
Conflicts are noted in lines 5 and 8, and between lines 4 and 9; however, possibility of direct symmetry is noted in the top four lines, which indicates that the recoveries in these lines could well be homogeneous, not having been affected by vagaries of the keying. Transferring values among these four lines, we will develop the reconstruction matrix into the following, in which the cipher components are slides of what is patently a keyword-mixed sequence (derived values in lower case):
| P: | A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | C | е | f | g | m f |
N | 0 | q | t | Z | Н | - | 1 | ||||||||||||||
| 2 | L | C | е | f | g | m | n | 0 | q | t | Z | h | |||||||||||||||
| 3 | 1 | C | е | F | G | m | n | 0 | Q | T | z | h | |||||||||||||||
| 4 | С | E | F | g | M | n | 0 | q | T | z | h | 1 |
Our work sheet will now look as illustrated in Fig. 17. which includes the values in the first four columns obtained by direct symmetry shown in lower case:
- Y F W F M R I Q M X X E L M J . . . 16. G O E Q B Q V O C F X E S N H . . . 2. H W W T T E C T D O Z F D O V . . . 17. W T S R G X M Z T V S J Q L X . . . S 3. TPYFKSOVWIHFNCJ...18. WTEVFCIBTSPRCAT... 4. Y P E P S N L S K Z N V T J B . . . 19. Z C V Y M B V N Y W Q U Z G U . . . MMAND RE 5. E A Q U Z D V E S K C I U P A . . . 20. Z C T T Z W C T T I K H Q U T . . . REPORT N 6. Z C G M W T N B I M K U S N L . . . 21. Z C C T S N E S K O U B M P T . . . REGIMENT RECOMMEND 7. EPDOZFDOVBILVLW . . . 22. AFESJONKTDVESKC . . . h e 8. EPTLESACRBMPTPF...23. ZCFFDTNPFDHDTPF... REFERENCE 9. W M L S O T O Z E E J Z G V K . . . 24. V Z I E X R X R F F U N T Q E . . . l a 10. ZCFFDCFRJWHLPHX...25. EPSNLSKLOHWPTRG... Ι 11. H C Q E D T P Y I L N R E M V . . . 26. Y T S V W L S T L E S A C R B . . . SENDRE 12. C L C T Z I K S O E O Z C T T . . . 27. W A Z X Z Q A C H Q U T L S T . . . ACCORDING 13. H C Q E F D K I F Q W O C L M . . . 28. N O F T Z N L H Q U T J H Z A . . . SEND I INFORMATION E 14. EPTWKSUZNVVAUCS...29. VRCWKMOLNXWSDOL... 15. ZABMZHGOFXQIGMM...30. SPRCPFXEOJCQFWM... I R Ε G
FIGURE 17
e. At this point more plain text could be assumed in the messages from the fragments already present; the cipher component would be recovered in its entirety, the basic key determined, and the cause of the key interruptions (as manifested by the apparent garbles) ascertained. Or, as another
SECRET
approach, we might take an introspective look at the first 5 letters of matched plain and cipher of the following three message beginnings:
10. Z C F F D . . . . . R E F E R 20. Z C T T Z . . . . . R E P O R. 28. N O F T Z . . . . . I N F O R
We note the $D_c=R_p$ and $Z_c=R_p$ in position 5 of Messages 10 and 20, and observe that, if the system employs a ciphertext interruptor, it may be either $F_c$ or $T_c$ ; but if $TZ_c=0R_p$ in Messages 20 and 28 is causal, $F_c$ and $T_c$ are eliminated and therefore there is no ciphertext interruptor in the cryptosystem. We then note the common $F_c=F_p$ between Messages 10 and 28 and the fact that in position 5 of Message 28 $Z_c=R_p$ , and we may conclude that, if a plaintext interruptor is present, it must be $O_p$ . We find this to be true, and when we finish the solution of the problem we find the cipher component to be our perennial friend, the HYDRAULIC . . . XZ sequence, and the basic key to be CALIFORNIAGOLDR (USH) .
- Additional remarks.—a. We have seen in the preceding paragraph a demonstration of solution of only one irregularly keyed system involving unknown cipher alphabets. The solution involved a set of very fortunate circumstances indeed, all of which were happily present awaiting rapid exploitation by the cheerful cryptanalyst. Modern cryptanalysis is quite often contingent upon miracles—minor miracles for minor systems, and healthy miracles for some of the complex systems encountered in present-day operations. When we come right down to it, all cryptanalysis is astonishing; it certainly is so to a layman, and it is so even to an expert—if he pauses long enough from his breaking of one system after another to marvel at the phenomenal luck he has had, shuddering at the thought of what would have happened if (i.e., if the enemy had done this instead of that, if he had used this instead of that, and if . . .). On the other hand, all cryptanalysis is quite commonplace: 22 after all, messages have been encrypted with certain invariant mathematico-philosophical-procedural elements, and all the cryptanalyst does is to discover and exploit these elements. And, in retrospect, after a problem has been solved, we often shrug our shoulders and say "Well, how else would one have done it?" Many systems of the types treated in this volume could be virtually unsolvable, or might appear to be so, if only a small amount of traffic is available for study, and if little or nothing is known about the nature of the cryptosystem. However, as happens time and again in actual operations, Fortuna smiles and the incredible is shorn of its prefix.
- b. Operationally, cryptodilemmas are resolved by the exploitation of contingencies which are by now well-known to the reader: (1) messages in the same or nearly the same keys; (2) depths and partial depths; (3) polygraphic repetitions; (4) cribs; (5) various kinds of cryptographic errors; (6) isologs; (7) matched plain and cipher; (8) isomorphs; (9) indicators. Each problem presents a very special case, and therefore demands its own special requirements for solution.
- c. Most of the types of aperiodic substitution discussed in this chapter are rather unsuitable for practical military usage. Encipherment is slow and subject to error. In some cases encipherment can be accomplished only by a single-letter operation. For, in interruptor systems, if the interruptor is a cipher letter the key is interrupted by a letter which cannot be known in advance; if the interruptor is a plaintext letter, while the interruptions can be indicated before encipherment is begun, the irregularities occasioned by the interruptions in keying cause confusion and quite materially retard the enciphering process. In deciphering, the rate of speed would be just as slow in either method. It is obvious that one of the principal disadvantages in all these methods is that if an error in transmission is made, if some letters are omitted, or if anything happens to the interruptor letter, the message becomes difficult or impossible to decipher by the ordinary cipher clerk. In spite of all these objections, plus the fact that the degree of cryptosecurity attainable by most of these methods is not sufficient for military purposes, these systems have been and are still occasionally encountered—which is what makes the cryptologic world go round.
<sup>22 It must have been a deep thinker who first uttered the statement that "all problems in cryptanalysis, like mathematics, are either trivial or impossible."
CHAPTER IV
(b)(1)
(b) (3) - 18 USC 798
(b) (3) - 50 USC 3024(i)
(b) (3) - P.L. 86 - 36
CIPHERTEXT AUTOKEY SYSTEMS
| Paragraph | |
|---|---|
| The cryptography of autokey encipherment. | * 21 |
| Solution of ciphertext autokeyed cryptograms when known cipher alphabets are emplo | yed 22 |
| Principles of solution by frequency analysis | 23 |
| Example of solution by frequency analysis | 24 |
| Solution by means of isomorphs | |
| Solution of isologs involving the same pair of unknown primary components | 26 |
| 27 | |
| Further remarks on ciphertext autokey systems | 28 |
- The cryptography of autokey encipherment.—a. The mechanics of autokey encipherment were treated briefly in the preceding volume. In autokey systems there are two possible sources for successive key letters: the cipher text or the plain text of the message itself. In either case, the initial key letter or key letters are supplied by prearrangement between the correspondents, or are designated by means of an indicator; after that, the text letters that are to serve as the key are displaced 1, 2, 3 . . . intervals to the right, depending upon the length of the prearranged key.
- b. An example of ciphertext autokey encipherment is shown below, wherein the cipher alphabets are direct standard alphabets, and the single letter X is the prearranged initial key:
K: X Q X F W Z Q U A I U Y L E G U G S S F I X L D W I W R Z M
P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . .
C: Q X F W Z Q U A I U Y L E G U G S S F I X L D W I W R Z M S
FIGURE 18a
Instead of having a single letter serve as the initial key, a word or even a long phrase may be used, as in the example below wherein the word FORTUNE is used as the initial key:
K: F O R T U N E Y V Z K X E I E D L O K X K S P X O X A Z G H
P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . .
C: Y V Z K X E I E D L O K X K S P X O X A Z G H Q A L V H T N
FIGURE 18b
Sometimes only the last cipher letter resulting from the use of the prearranged key word is used as the key letter for enciphering the autokeyed portion of the text. Thus, in the preceding example, the plain text beginning GIMENT . . . would be enciphered differently as follows:
K: FORTUNE IOWIMZSUIUGGTWLZRKWKFNAP: THIRDREGIMENTCOMMANDPOSTMOVING...
C: YVZKXEIOWIMZSUIUGGTWLZRKWKFNAG
FIGURE 18c
c. In plaintext autokey encipherment the procedure is quite similar, as is shown in the following example wherein the prearranged initial key is the letter X:
K: X T H I R D R E G I M E N T C O M M A N D P O S T M O V I N P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . . C: Q A P Z U U V K O U Q R G V Q A Y M N Q S D G L F A J D V T
FIGURE 19a
<sup>1 Cf. subpar. 99e on pp. 310-311 of Military Cryptanalytics, Part II.
SEORET
If the word FORTUNE were used as the initial key, the plain text would be enciphered as follows:
K: FORTUNE THIRDREGIMENT COMMANDPOS
P: THIRDREGIMENT COMMANDPOSTMOVING...
C: YVZKXEIZPUVQKGUUYEAWRCEFMBYXBY
FIGURE 19b
d. In the foregoing examples, direct standard alphabets were used; however, mixed alphabets, either interrelated or independent,2 may be used just as readily. Furthermore, instead of the ordinary type of cipher alphabets, the cryptographic process may employ a mathematical process of addition, but the difference between the latter process and the ordinary one using sliding alphabets is more apparent than real. For example, let us consider the following numerical sequence for the 26 letters
$\begin{array}{cccccccccccccccccccccccccccccccccccc$
and let the plaintext message be the same as before. Let us assume that the cryptographic rules prescribe that the first plaintext letter will be self-enciphered,3 and that each cipher letter from that point on is produced in turn by finding the sum (mod 26) of the numerical equivalents of the preceding cipher letter and the plaintext letter to be enciphered; in other words, a type of numerical ciphertext autokey system. This is shown in the diagram below, wherein P' denotes the numerical equivalents of the plain text, C' the sum of the key and the numerical (i.e., intermediate) plain text, and C the conversion into letters of the intermediate cipher text C'.
\begin{array}{cccccccccccccccccccccccccccccccccccc
FIGURE 20a
e. That the difference between the types of encipherment in the preceding subparagraph and the ordinary method of ciphertext autokey encipherment is illusory is demonstrated by the example in Fig. 20b, below:
K: ZTVACFMHJTFVJBPEHNTGMCHTOIZVAT
P: THIRDREGIMENTCOMMANDPOSTMOVING..
C: TVACFMHJTFVJBPEHNTGMCHTOIZVATC
FIGURE 20b
In this example, the plain and cipher components are keyword-mixed sequences based upon HYDRAULIC, and $Z_p$ is the index letter against which the key letters in the cipher component are set; the cryptographic results are identical to those obtained in Fig. 20a, above.
- f. Since the analysis of ciphertext autokey systems is usually easier than the analysis of plaintext autokey systems, the former will be the first to be discussed.
- Solution of ciphertext autokeyed cryptograms when known cipher alphabets are employed.—a. First of all, it is to be noted that if the cryptanalyst knows the cipher alphabets which were employed in encipherment, the solution hardly presents any problem. It is only necessary to decipher the message beyond the key-letter or key-word portion and the initial part of the plain text enciphered by this key letter or key word can be filled in from the context.
SECRET
<sup>2 For instance, an autokey system might incorporate independent, random alphabets such as those illustrated in Fig. 33 on p. 70.
<sup>3 This, on a numerical scale, is tantamount to the effect of a key of $\emptyset$ .
(1) For example, let us consider the following beginning of an intercepted message:
QXFWZ QUAIU YLEGU GSSFI...
On the assumption of ciphertext autokey involving direct standard alphabets, if we write the cipher text as key letters, displaced one interval to the right, we obtain the following decipherment:
K: QXFWZQUAIUYLEGUGSSF
C: Q X F W Z Q U A I U Y L E G U G S S F I . . .
P: HIRDREGIMENTCOMMAND
The introductory key letter required to make $Q_c = T_p$ is found to be $X_k$ .
(2) As a second example, let us consider the following beginning of a cryptogram suspected to have been enciphered by ciphertext autokey with direct standard alphabets:
BPAUV NLFJA LYMLQ NAELR...
Assuming an introductory key of one letter, we obtain the following decipherment:
K: BPAUVNLFJALYMLQNAEL
C: BPAUVNLFJALYMLQNAELR...
P: OLUBSYUERLNOZFXNEHG
Nothing. We now assume that the introductory key consisted of two letters, and we get the following results:
K: BPAUVNLFJALYMLQNAE
C: BPAUVNLFJALYMLQNAELR...
P: ZJVTQSYVCYBNECKRLN
Still nothing. We make several more trials, and finally, on the assumption of an introductory key of 8 letters, the following is obtained.
K: BPAUVNLFJALY
C: BPAUVNLFJALYMLQNAELR...
P: ILLERYFIREAT
It is clear that the introductory key is 8 letters in length. Doing what comes naturally,
K: NUMBPAUVNLFJALY
C: BPAUVNLFJALYMLQNAELR...
P: ARTILLERYFIREAT
shows that the introductory key ends with NUM; now with but little experimentation, either with the letters of the key or with the beginning of the message plain text, we obtain the complete solution:
K: ALUMINUMBPAUVNLFJALY
C: BPAUVNLFJALYMLQNAELR...
P: BEGINARTILLERYFIREAT
(3) In a third case, we will assume that the following is the beginning of an intercepted message:
DITGC MGTZB PCVDQ KYSKP...
SFORET
Again assuming direct standard alphabets, writing the cipher text as key letters displaced one interval to the right and deciphering, we obtain the following:
K: DITGCMGTZBPCVDQKYSK
C: DITGCMGTZBPCVDQKYSKP...
P: FLNWKUNGCONTINUOUSF
We note the plain text "CONTINUOUS F..." emerging, preceded by the NG which is probably ING; this indicates that ciphertext autokey is involved with an initial key of 7 letters, and that the last letter of the initial key is used to start the autokeyed portion. After a little experimentation with the initial portion of the message text and the key, we recover the key word and the first word of the message, as follows: 5
K: M E R C U R Y | G T Z B P C V D Q K Y S K C: D I T G C M G T Z B P C V D Q K Y S K P . . . P: R E C E I V I N G C O N T I N U O U S F
- b. A mechanical method of solution for ciphertext autokeyed cryptograms when the components are known sequences may be of interest. The method involves the use of sliding alphabet strips aligned in such a manner that, as one progresses from left to right across the strips, each key letter is set opposite the letter k on the preceding strip: 6 the plain text will appear to the left of the pertinent cipher letter on each strip. In other words, what we have is a mechanical method of correlating the letters of the key, cipher, and plain text; the method is best understood by examples.
- (1) In Fig. 21 is illustrated the arrangement of standard-alphabet strips for the first 10 letters of putative key, QXFWZQUAIU, for the message beginning given in subpar. a(1), above. If we assume that a one-letter introductory key has been used, the key letters just named were used to key the 2d through 11th cipher letters, XFWZQUAIUY; therefore we search for these cipher letters consecutively across the strips and we note the letters to their immediate left. In this case the plain text HIRDREGIME is manifested and the problem is solved.
<sup>4 The I of ING gives a key of Y, which should be preceded by a T, A, L, or very few other letters.
<sup>5 The key word and the first word of the message may be recovered by working backwards from $ING_p$ , or by assuming various initial digraphs for the plain text or the key; a trial of $RE_p$ for the message beginning would yield $ME_k$ , and we could go on from here to read this "depth of one."
$^{6}$ This is under the assumption that $A_{n}$ is the index letter in the cryptographic equations.

FIGURE 21 FIGURE 22a FIGURE 22b
(2) The next example in Fig. 22a illustrates the strip arrangement for the first 10 letters of key, BPAUVNLFJA, for the message beginning given in subpar. a(2). If a one-letter introductory key has been used, these key letters apply to the 2d through 11th cipher letters, PAUVNLFJAL; the decipherment of these letters is found to their immediate left, which is OLUBSYUERL, obviously not plain text. On the same diagram we then search for the decipherment of the 3d through 12th letters, assuming that a two-letter introductory key was employed; again this yields no valid plain text. Finally, on the 8th trial, on the assumption that an 8-letter introductory key is involved, we obtain the plain text ILLERY FIRE; this is shown in Fig. 22b.
(3) For the third and final example, there is illustrated in Fig. 23a the strip arrangement for the first 10 letters of assumed key, DITGCMGTZB, for the message beginning given in subpar. a(3).
| (K): (D I T G C M G T Z B) (C): (I T G C M G T Z B P) |
(Z B P C V D Q K Y S) (B P C V D Q K Y S K) |
|---|---|
| A D L E K M Y E X W X B E M F L N Z F Y X Y C F N G M O A G Z Y Z |
A Z A P R M P F P N F B A B Q S N Q G Q O G C B C R T O R H R P H |
| C F N G M O A G Z Y Z D G O H N P B H A Z A |
DCDSUPSISQI |
| E H P I O Q C I B A B | EDETVQTJTRJ |
| FIQJPRDJCBC | FEFUWRUKUSK |
| GJRKQSEKDCD | GFGVXSVLVTL |
| HKSLRTFLEDE | HGHWYTWMWUM |
| ILTMSUGMFEF | IHIXZUXNXVN |
| JMUNTVHNGFG | JIJY AV YOYWO |
| KNVOUWIOHGH | K J K Z B W Z P Z X P |
| LOWPVXJPIHI | L K L A C X A Q A Y Q |
| MPXQWYKQJIJ | MLMBDYBRBZR |
| NQYRXZLRKJK | N M N C E Z C S C A S |
| O R Z S Y A M S L K L | 0 N O D F A D T D B T |
| PSATZBNTMLM | POPEGBEUECU |
| Q T B U A C O U N M N | QPQFHCFVFDV |
| RUCVBDPVONO | RQRGIDGWGEW |
| SVDWCEQWPOP | SRSHJEHXHFX |
| TWEXDFRXQPQ | TSTIKFIYIGY |
| UXFYEGSYRQR | UTUJLGJZJHZ |
| VYGZFHTZSRS | V U V K M H K A K I A |
| WZHAGIUATST | WVWLNILBLJB |
| XAIBHJVBUTU | XWXMOJMCMKC |
| YBJCIKWCVUV | YXYNPKNDNLD |
| ZCKDJLXDWVW | ZYZOQLOEOME |
| (P):(F L N W K U N G C O) | $(C\ O\ N\ T\ I\ N\ U\ O\ U\ S)$ |
| Figure 23a | FIGURE 23b |
Nothing is seen here, so a number of additional trials is made, sliding the assumed key over successive 10-letter segments of the cipher text, all without success. We could now assume that an introductory key word was used, and that the autokeyed portion began with the last letter of cipher text after the end of the introductory key. With this in mind, we take as hypothetical key some text after the beginning of the cryptogram, say the 9th through 18th letters, ZBPCVDQKYS; trying this as key for the 10th through 19th letters, BPCVDQKYSK, we are successful on the first trial as shown in Fig. 23b with the emergence
of the plain text CONTINUOUS.7
c. The foregoing mechanical method serves in helping to understand the mechanics of solution of ciphertext autokey encipherment involving known components. A simpler approach, however, is the use of the method of searching for the location of a probable word, as illustrated in the previous volume.8
<sup>7 Had we been a little more observant, we could have noticed what appears to be a good plaintext fragment NGCO in the very first trial in Fig. 23a; this was a contrived lapse of observation, the better to illustrate a pedagogical point in Fig. 23b.
<sup>8 Cf. Subpar. 22d on pp. 41-42 of Military Cryptanalytics, Part II.
(1) For example, if we were to test the message beginning given in subpar. a(2), above, for the possibility of ciphertext autokey involving direct standard alphabets and an introductory key of unknown length, we would construct the following diagram:
| 5 | 10 | 20 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | 3 | P | A | U | V | N | L | F | J | Α | L | Y | M | L | Q | N | A | Е | L | R |
| В | 0 | Z | T | U | M | K | E | Ī | Z | K | X | L | K | P | M | Z | D | K | Q | |
| P | L | F | G | Y | W | Q | Ŋ | Ŧ | W | J | X | W | В | Y | L | P | W | C | ||
| A | U | V | N | L | F | J | À | Ť | Y | M | L | Q | N | A | E | L | R | |||
| บ | В | T | R | L | Ρ | G | R | Œ | S | R | W | T | G | K | R | X | ||||
| V | S | Q | K | 0 | F | Q | D | R | Q | V | S | F | J | Q | W |
FIGURE 24
In this diagram, the top row contains the cipher letters, and at the left are the first five cipher letters (the putative key); the row just below the line consists of the decipherments of the cipher letters with the first key letter; the second row below the line consists of the decipherments with the second key letter; and so forth. On a diagonal under the 9th cipher letter may be seen the plaintext fragment ILLER, proving that the introductory key was 8 letters in length.
(2) Taking as another example the message beginning given in subpar. a(3), above, we construct the following diagram:
| 5 | 10 | 20 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Γ | ) | Ι | T | G | C | M | G | T | Z | В | P | C | V | D | Q | K | Y | S | K | P |
| D | F | Q | D | Z | J | D | Q | W | Y | M | Z | S | A | N | Н | V | P | Н | M | |
| I | Ĺ | Y | U | E | Y | L | R | T | Н | U | N | V | I | C | Q | K | C | Н | ||
| Т | N | J | T | N | A | G | I | W | J | C | K | X | R | F | Z | R | W | |||
| G | W | G | A | N | T | V | J | W | P | X | K | E | S | M | E | J | ||||
| C | K | E | R | X | Z | N | A | T | В | 0 | I | W | Q | I | N |
FIGURE 25
Nothing of significance is seen, so, testing the possibility of autokeying from the last letter of a long introductory key, we construct the diagram shown below, in which we have arbitrarily taken as tentative key elements the cipher letters starting at position 11:
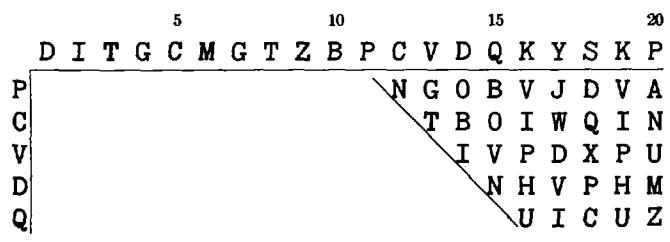
FIGURE 25b
On the very first diagonal, the plain text fragment NTINU manifests itself, showing that the single-letter offset keying begins at least by the 12th cipher letter, if not before (it actually begins at the 8th position, after a 7-letter introductory key, as can be quickly determined).
d. The index letter was $A_p$ in the foregoing examples; if some other letter were used as the index letter, only a slight modification of the general procedure is necessary. Let us study the following example enciphered with direct standard alphabets, with $Q_p$ as the index letter:
K: X A R J K X Y M C U Q E B E Q O K G Q N A Z X Z C Y W B T Q P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . . C: A R J K X Y M C U Q E B E Q O K G Q N A Z X Z C Y W B T Q G
<sup>9 Note that, although the plain text and introductory keys are identical with those of the example in Fig. 18a, nevertheless the two cipher texts are not isomorphic, since the change of index letter eliminates any causal isomorphism between the two versions.
SEGRET-
If we had only the cipher text, and assumed that it was the result of ciphertext autokey encipherment with direct standard alphabets and a one-letter introductory key, we would perform the following decipherment on the basis of $A_p$ as the index letter:
K: ARJKXYMCUQEBEQOKGQNC:ARJKXYMCUQEBEQOKGQNA..
"P": RSBNBOQSWOXDMYWWKXN
The "decipherment" does not yield plain text; but if we complete the plain-component sequence on the result of this decipherment, we will obtain the true plain text on one of the generatrices, as shown in the diagram below:
RSBNBOQSWO STCOCPRTXP TUDPDQSUYQ UVEQERTVZR VWFRFSUWAS WXGSGTVXBT XYHTHUWYCU YZIUIVXZDV ZAJVJWYAEW ABKWKXZBFX BCLXLYACGY CDMYMZBDHZ DENZNACEIA EFOAOBDFJB FGPBPCEGKC GHQCQDFHLD *HIRDREGIME IJSESFHJNF JKTFTGIKOG KLUGUHJLPH LMVHVIKMQI MNWIWJLNRJ NOXJXKMOSK OPYKYLNPTL PQZLZMOQUM QRAMANPRVN
- Principles of solution by frequency analysis.—a. It is apparent that repetitions in ciphertext autokey systems will not be nearly as plentiful in the cipher text as they are in the plain text, because in these systems before a repetition can appear two things must happen simultaneously. First, of course, the plaintext sequence must be repeated, and second, one or more ciphertext letters (depending upon the length of the introductory key) immediately before the second appearance of the plaintext sequence must be identical with one or more ciphertext letters immediately before the first appearance of the plaintext sequence. This can happen only as the result of chance. In the following example the introductory key is the single letter X, and the components are direct standard alphabets employed in the usual Vigenère manner:
K: X C K B T M D H N V H L Y . . . . K D K S J M D H N V H L Y P: F I R S T R E G I M E N T . . . . T H I R D R E G I M E N T C: C K B T M D H N V H L Y R . . . K D K S J M D H N V H L Y R
The repeated plaintext word, REGIMENT, has only 8 letters but the repeated ciphertext sequence contains 9, of which only the last 8 letters actually represent the plaintext repetition. In order that the word REGIMENT be enciphered by DHNVHLYR the second time this word appeared in the text, it was necessary that the key letter for its first plaintext letter, R, be M both times; no other key letter will produce the same cipher sequence for the word REGIMENT in this case. Each different key letter for enciphering the first letter of REGIMENT will produce a different encipherment for the word, so that the chance for a repetition in this case is 1 in 26. This is the principal cause for the reduction in repetitions in this system. If an introductory key of two letters were used, it would be necessary that the two cipher letters immediately before the second appearance of the repeated word REGIMENT be identical with the two cipher letters immediately before the first appearance of the word; therefore the chance for a repetition in this case is 1 in $26^2$ . In general, then, an n-letter repetition in the cipher text, represents an (n-k) letter repetition in the plain text, where n is the length of the ciphertext repetition and k is the length of the introductory key.
b. There is a second phenomenon of interest in connection with ciphertext autokey systems. Let the letter opposite which the key letter is placed (when using sliding components for encipherment) be termed, for convenience in reference, the "base letter." Normally the base letter is the initial letter of the plain component, but it has been pointed out in the preceding volume that this is only a convention. Now when the introductory key is a single letter, if the base letter occurs as a plaintext letter its cipher equivalent is identical with the immediately preceding cipher letter; that is, there is produced a double letter in the cipher text, no matter what the cipher component is and no matter what the key letter happens to be for that encipherment. For example, using the HYDRAULIC . . . XZ sequence for both primary components, with H (the initial letter of the plain component) as the base letter, and using the introductory key letter X, the following encipherment is produced:
K: X U N F F T T V K U H H M B N P: I F T H E H Y P O T H E S I S . . C: U N F F T T V K U H H M B N E
Note the doublets FF, TT, and HH. Each time such a doublet occurs it means that the second letter represents Hp, which is the base letter in this case (the initial letter of the plain component). Now if the base letter happens to be a high-frequency letter in normal plain text, for example the letter E or T, then the cipher text will show a large number of doublets; if it happens to be a low-frequency letter then the cipher text will show very few doublets. In fact, the number of doublets will be directly proportional to the frequency of the base letter in normal plain text. Thus, if the cryptogram contains 1,000 letters there should be about 72 occurrences of doublets if the base letter is A, since in 1,000 letters of plain text there should be about 72 A's. Conversely, if a cryptogram of 1,000 letters shows about 72 doublets, the base letter is likely to be A; if it shows about 90, it is likely to be T, and so on. Furthermore, when a clue to the identity of the base letter has been obtained in this manner, it is possible immediately to insert the corresponding plaintext letter throughout the text of the message. The distribution of this letter may not only serve as a check (if no inconsistencies develop) but may also lead to the assumption of values for other cipher letters.
c. When the introductory key is two letters, then this same phenomenon will produce groups of the formula ABA, where A and B may be any letters, but the first and third must be identical. The occurrence of patterns of this type in this case indicates the encipherment of the base letter.
d. The phenomenon noted above can be used to considerable advantage in the solution of ciphertext autokey cryptograms. For instance, if it is known that the ordinary Vigenère method of encipherment $(\theta_{\mathbf{k}/2} = \theta_{1/1}; \theta_{\mathbf{p}/1} = \theta_{0/2})$ is used, then the initial letter of the plain component is the base letter. If, further, it is known that the plain component is the normal A-Z sequence, then the base letter is A and a word such as BATTALION will be enciphered by a group having the pattern AABCCDEFG. If the plain component is a mixed sequence and happens to start with the letter E, then a word such as ENEMY would be enciphered by a sequence having the pattern AABBCD.10 Sequences such as these are, of course, idiomorphic and if words yielding such idiomorphisms are frequent in the text there will be produced in the latter several
SEORET.
10 Six letters are shown because the idiomorphism in this case extends over that many letters.
or many cases of isomorphism. When these are analyzed by the principles of indirect symmetry of position, a quick solution may follow.
- e. A final principle underlying the solution of ciphertext autokeyed cryptograms remains to be discussed; it concerns the nature of the frequency distribution required for the analysis of such cryptograms. Consider the message beginning illustrated in Fig. 18a in subpar. 21b. It happens that the letter We occurs three times in this short message beginning and, because of the nature of the ciphertext autokeying method, this letter must also appear three times in the key. Now it is obvious that all plaintext letters enciphered by key letter Wk will be in the same cipher alphabet; in other words, if the key text is cipher text offset one letter to the right of the cipher text, then every cipher letter which immediately follows a We in the cryptogram will belong to the same cipher alphabet, and this alphabet may be designated conveniently as the W cipher alphabet. Now if there were sufficient text, so that there were, say, 30 to 40 Wc's in it, then a frequency distribution of the letters immediately following the Wc's will exhibit monoalphabeticity. What has been said of the letters following the Wo's applies equally well to the letters following all the other letters of the cipher text, the Ac's, Bc's, Cc's, and so on. In short, if 26 distributions are made, one for each letter of the alphabet, showing the cipher letter immediately succeeding each different letter of the cipher text, the text of the cryptograms can be allocated into 26 uniliteral, monoalphabetic frequency distributions which can be solved by frequency analysis, provided that there are sufficient data for this purpose.
- (1) The foregoing principle has been described as pertaining to the case when the introductory key is a single letter; that is, when the key text is offset or displaced but one interval to the right of the cipher text. But it applies equally to cases wherein the key text is offset more than one interval, provided that the frequency distributions are based upon the proper interval, as determined by the displacement due to the length of the introductory key. For instance, suppose the introductory key consists of two letters, as in the following example.
K: XZMRHFHGFNQRXOMRMVWEE P: RELIABLEINFORMATION... C: MRHFHGFNQRXOMRMVWEE...
The key text in this case is offset two intervals to the right of the cipher text; therefore if we made frequency distributions by taking the cipher letters one interval to the right of a given cipher letter (each time that letter occurs), these distributions will not be monoalphabetic because some letter not related at all to the given cipher letter is the key letter for enciphering the letter one interval to the right of the letter. For example, note the three Rc's in the foregoing illustration. The first Rc is followed by Hc, representing the encipherment of Lp by Mk; the second Rc is followed by Xc, representing the encipherment of $F_p$ by $Q_k$ ; the third $R_c$ is followed by $M_c$ , representing the encipherment of $A_p$ by $M_k$ . The three cipher letters H, X, and M are here entirely unrelated and do not belong to the same cipher alphabet because they represent encipherments by three different key letters. On the other hand, the cipher letters two intervals to the right of the Rc's, viz., F, O, and V, are in the same cipher alphabet because these cipher letters are the results of enciphering plaintext letters I, O, and T, respectively, by the same key letter, R. It is obvious, then, that when the introductory key consists of two letters and the key text is displaced two intervals to the right of the cipher text, the proper frequency distributions for monoalphabeticity will be based upon the letter at the second interval to the right of each cipher letter. Likewise, if the introductory key consists of three letters and the key text is displaced three intervals to the right of the cipher text, the distributions must be based upon the third interval, and so on, in each case the interval used corresponding to the amount of displacement between key text and cipher text.
(2) Conversely, in solving a problem of this type, when the length of the introductory key and therefore the amount of displacement are not known, the appearance of the frequency distributions based upon various intervals after each different cipher letter will disclose this unknown factor, since only one set of distributions will exhibit monoalphabeticity and the interval corresponding to that set will be the correct interval.
- Example of solution by frequency analysis.—a. It will be assumed that previous studies have disclosed that the enemy is using ciphertext autokey systems; it will be further assumed that these studies have also disclosed that (1) the introductory key is usually a single letter, (2) the usual Vigenère method of employing sliding primary components is used, and (3) the plain component is usually the normal A-Z sequence, the cipher component a mixed sequence which changes daily. The following cryptograms, all of the same date, have been intercepted:
Message No. 1
| I | J | X | W | X | E | E | C | D | Α | C | N | Q | E | Т | U | K | N | M | V | D | Ι | W | P | P | Q | Z | S | X | D |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Н | I | F | E | L | N | N | J | J | I | D | Ι | V | E | Y | G | T | C | Z | M | Ε | Н | Η | L | M | R | V | C | U | R |
| G | D | Ι | E | Q | S | G | T | Α | R | J | J | Q | Q | Y | C | A | R | P | Н | M | G | L | D | Y | F | Y | Т | C | D |
| G | Y | F | K | R | F | K | S | E | T | T | D | I | Q | K | K | M | L | T | U | R | Q | G | G | N | K | M | K | Ι | X |
| J | X | W | K | Α | 0 | K | N | Т | В | Т | Z | J | 0 | Q | Y | S | C | D | Ι | D | G | E | Т | X | G |
Message No. 2
| G | R | V | R | M | Z | W | K | X | G | W | Ρ | C | K | K | R | M | X | A | N | J | C | C | X | U | R | T | N | J | U |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | K | 0 | В | L | N | L | M | W | K | Y | Y | Z | J | U | C | S | U | Н | F | F | Н | I | J | A | Q | В | M | L | Т |
| P | U | R | R | S | U | E | Q | E | V | Z | E | Y | G | C | F | F | N | F | I | В | W | N | Y | S | T | C | E | Т | Р |
| D | G | Т | T | Z | R | R | Q | Н | Q | Α | 0 | 0 | X | D | В | U | Y | N | K | L | В | W | C | D | G | G | K |
Message No. 3
R W K A O L T C J M Z D K V U J C D D Y B Z E L M M W T Q O H Q V G X C H O L M W V G R K I B R X D L A Q Y U K I R O Z T Q Y U
Message No. 4
X J J P M L T Z K X E C A Q Z N T T O C O N D U C T U T C V G R J P F F D I P P D I X C E S E T W W S U M U J C S L G X H X M O Z E K A Q I S U A O
Message No. 5
GISUH WZHST TZOID DHOOV NBTJG XCTBS FKIRH MMVYM IIVUU CZMJE HAGIE WMEHH PPDQZ LMWKY GBOIW PSFAJ UQZHZ MTFHZ OBCCX NNDGI MLACZ ROVDI WPVIB ESJOC KBJHQ MUZEL YOOVU JWKIE IBBOZ FORSA JLNQM BQ
Message No. 6
TBJPA ARYYP VHIDI TUXNJ MXGSS BDAQY MMTTF UUNMG QPUXM OVUYE CECZM MWOHC FOBHV NKAZC KM
Message No. 7
TBJPA QAAZT RXALX FKKME IAABD SFTQT CJJGJ OVMRG LVWTT JUAWL XUKTX GGBOX MXDID SPBSF LYZKC F
51
SECRET-
b. A distribution table is now compiled, the results of which are shown in Fig. 26, below; in originally making the distribution, tallies had been recorded in the appropriate cell in the pertinent horizontal line of the table to indicate the cipher letter which immediately followed each occurrence of the letter to which that line applies. Obviously, the best method of compiling the data is to treat the text biliterally, taking the first and second letters, the second and third letters, and so on, distributing the digraphs as tallies in a digraphic distribution.
| _ | A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z | N | _φ | I.C. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 3 | 1 | 2 | 1 | 3 | 1 | 1 | 1 | 4 | 6 | 3 | 1 | _ | 2 | 29 | 64 | 2.05 | ||||||||||||
| В | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 4 | 1 | 1 | 2 | 2 | 1 | 2 | 2 | 1 | 24 | 26 | 1.22 | ||||||||||
| C | 2 | 2 | 5 | 3 | 3 | 1 | 2 | 3 | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 4 | 35 | 62 | 1.35 | ||||||||||
| D | 2 | 1 | 2 | 5 | 2 | 10 | ) | 1 | 1 | 1 | 2 | 1 | 2 | 30 | 120 | 3.59 | |||||||||||||
| E | 4 | 1 | 1 | 3 | 2 | ? | 1 | 3 | 2 | 2 | 5 | 1 | 1 | 2 | 28 | 52 | 1.79 | ||||||||||||
| F | 1 | 1 | 1 | 4 | 2 | 1 | 4 | 1 | 1 | 2 | 1 | 1 | 1 | 21 | 28 | 1.73 | |||||||||||||
| G | 2 | 1 | 1 | 1 | 3 | 3 | 51 | 1 | 2 | 1 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 29 | 32 | 1.02 | |||||||||
| Н | 1 | 1 | 1 | 2 | 3 | 5 | 2 | 2 | 2 | 3 | 1 | 1 | 1 | 1 | 2 | 23 | 22 | 1.13 | |||||||||||
| I | 1 | 4 | 5 | 5 | 1 | 1 | .2 | 1 | 1 | 2 | 1 | 1 | 2 | 3 | 3 | 33 | 70 | 1.72 | |||||||||||
| J | 1 | 3 | 1 | 2 | 1 | 2 | 4 | 1 | 2 | 3 | 4 | 1 | 4 | 1 | 2 | 32 | 56 | 1.47 | |||||||||||
| K | 4 | 1 | 1 | 5 | • | 3 | 1 | 4 | 2 | 1 | 2 | 1 | 1 | 1 | 2 | 2 | 31 | 58 | 1.62 | ||||||||||
| L | 2 | 1 | 1 | 1 | 5 | 3 | 4 | 1 | 2 | 2 | 22 | 44 | 2.48 | ||||||||||||||||
| M | 1 | 3 | 2 | 1 | .1 | 1 | 4 | 4 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 2 | 37 | 70 | 1.37 | ||||||||||
| N | 1 | 2 | 5 | ] | L | 4 | 3 | 1 | 2 | 2 | 2 | 2 | 1 | 21 | 28 | 1.73 | |||||||||||||
| 0 | 3 | 2 | 2 | 2 | ) | 1 | 2 | 1 | 3 | 1 | 1 | 5 | 2 | 3 | 28 | 4 8 | 1.66 | ||||||||||||
| P | 2 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 1 | 2 | 2 | 19 | 18 | 1.37 | ||||||||||||||
| Q | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 5 | 4 | 26 | 3 8 | 1.52 | ||||||||||
| R | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 1 | 25 | 18 | 0.78 | ||||||||||
| S | 1 | 1 | 1 | 2 | 4 | 1 | 1 | 1 | 1 | 1 | 2 | 5 | 1 | 22 | 3 6 | 2.03 | |||||||||||||
| T | 1 | 4 | 6 | 1 | 2 | 2 | 1 | 1 | 2 | 3 | 1 | 6 | 4 | 1 | 2 | 4 | 41 | 110 | 1.74 | ||||||||||
| U | 3 | 3 | 1 | 2 | 3 | 3 | 1 | 1 | 1 | 4 | 1 | 2 | 2 | 2 | 1 | 30 | 44 | 1.31 | |||||||||||
| V | 1 | 2 | 1 | 3 | 1 | 1 | 1 | 2 | 1 | 4 | 1 | 1 | 1 | 20 | 22 | 1.51 | |||||||||||||
| W | 1 | 6 | 1 | 1 | 1 | 1 | 4 | 1 | 2 | 1 | 1 | 1 | 1 | 22 | 44 | 2.48 | |||||||||||||
| X | 2 | 3 | 4 | 2 | 1 | 4 | 1 | 2 | 3 | 2 | 2 | 2 | 28 | 50 | 1.72 | ||||||||||||||
| Y | 1 | 1 | 1 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 22 | 16 | 0.90 | ||||||||||||
| Z | 1 | 1 | 1 | 4 | 1 | 2 | 2 | 2 | 5 | 1 | 1 | 2 | 1 | 2 | 1 | 27 | 42 | 1.56 | |||||||||||
| _ | 705 | 1218 | 42.85 |
FIGURE 26
c. The individual frequency distributions give every appearance of being monoalphabetic, which confirms the assumption that the enemy is using ciphertext autokey with a single-letter introductory key. The average I.C. of the rows of the matrix is $\frac{42.85}{26} = 1.65$ , which is fine;11 or, as a better approach, we could calculate the digraphic I.C. of the matrix by considering the sum (1218) of the $\phi$ values of Fig. 26 as the observed value of $\phi$ and substituting in the formula $\delta = \frac{676\Sigma f(f-1)}{N(N-1)} = \frac{676(1218)}{705\times704} = 1.66$ , again substantiating the same assumption.12 (This discrepancy between the two figures lies in the round-off errors introduced in obtaining an average I.C.)
SEGRET
ť
<sup>11 The arithmetic mean here suffices because the values of N involved are fairly close to one another; since, as has been previously stated, in ciphertext autokey systems the cipher letters are equiprobable (the over-all I.C. of the cipher text in this example is 1.005), a weighted mean is unnecessary.
<sup>12 Ciphertext autokey systems may therefore be identified statistically from the appropriate digraphic distribution (i.e., on the assumption of the correct length of the introductory key) by the fact that the digraphic I.C. will reflect the monographic I.C. of the language.
- d. The total number of letters of text is 712, comprising 705 digraphs. If the base letter is A, then there should be approximately $705 \times 7.4% = 52$ cases of doubled letters in the text. There are actually 53 doublets, which checks very well with the expectancy. The letter A is substituted throughout the text for the second letter of each doublet.
- e. The following sequence is noted at the beginning of Message No. 5:
$$\begin{array}{cccccccccccccccccccccccccccccccccccc$$
Assume that the sequence DDHOOVNBT represents the word BATTALION, in which case we will have the following key-cipher-plain relationships:
K: I D D H O O V N B T C: D D H O O V N B T P: B A T T A L I O N
If this assumption is correct, the frequency of $H_c$ in the D alphabet should be high, since $H_c=T_p$ ; the $H_c$ has only two occurrences. Likewise, the frequency of $O_c$ (= $T_p$ ) in the H alphabet should be high; it is also only two. The frequency of $V_c$ in the O alphabet should be medium or low, since it would equal $L_p$ ; it is five, which is too high. The rest of the letters of the assumed word are similarly checked against the appropriate frequency distributions, with the result that, on the whole, the assumption that the DDHOOVNBT sequence represents BATTALION does not appear to be warranted. Similar attempts are made at other points in the text, with the same or other probable words. Some of these attempts may have to be carried to the point where the placement of values in the tentative cipher component leads to serious inconsistencies. Finally, attention is fixed upon the following sequence in the second line of Message No. 6:
If we assume that this skeleton represents the word AVAILABLE, the following fragment of key, cipher, and plain should be true:
K: M M T T F U U N M G C: M T T F U U N M G P: A V A I L A B L E
Reference is now made to the appropriate frequency distributions to see how well the actual individual frequencies correspond to the expected ones; these data are tabulated in the diagram below:
| Alphabet | Assu | ımed | Freque | ncy | _ Approximation |
|---|---|---|---|---|---|
| θ c | θ, | Expected | Actual | ||
| M | T | V | Low | 2 | Fair |
| T | F | I | High | 2 | Fair |
| F | U | L | Medium | 1 | Good |
| U | N | В | Low | 1 | Good |
| N | M | L | Medium | 2 | Fair |
| M | G | E | High | 2 | Poor |
SECRET
This assumption of AVAILABLE cannot be discarded just yet. Let the values derivable from the assumption be inserted in their proper places in a cipher component, and, using the latter in conjunction with a normal A-Z sequence as the plain component, let an attempt be made to find corroboration for these values. The following placements may be made: 13
P: ABCDEFGHIJKLMNOPQRSTUVWXYZ C: M FG UN T
The letter $M_c$ appears twice in the cipher sequence and when this partially reconstructed cipher component is tested it is found that the value $L_p(N_k) = M_c$ is corroborated. Having the letters M, F, G, U, N, and T tentatively placed in the cipher component, it is possible to insert certain plaintext values in the text. For example, in the M alphabet, $F_c = D_p$ , $G_c = E_p$ , $U_c = 0_p$ , $N_c = P_p$ , and $T_c = V_p$ . In the F alphabet, $G_c = B_p$ , $U_c = L_p$ , $N_c = M_p$ , $T_c = S_p$ , and $M_c = X_p$ . The other letters yield additional values in the appropriate alphabets. The plaintext values thus obtainable are inserted in the cipher text. No inconsistencies appear and, moreover, certain good digraphs are brought to light. For instance, note what is manifested at the end of the third line of Message No. 5:
K: U Q Z H Z M T F H C: U Q Z H Z M T F H Z P: V T
Now if the letter H can be placed in the cipher component, several values might be added to this partial decipherment. We note that F and G are sequent in the cipher component; now let us suppose that H follows G therein, and we obtain the following:
K: UQZH ZMTFH C: UQZHZ MTFHZ P: VIC
Suppose the VIC is the beginning of VICINITY. This assumption permits the placement of A, C, L, and Z in the cipher component, as follows:
P: ABCDEFGHIJKLMNOPQRSTUVWXYZ C; MA FGH L ZUN T C
These additional values check in very nicely and presently the entire cipher component is reconstructed. It is found to be as follows:
P: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z C: M A B F G H J K L Q S V X Z U N D E R W O T Y P I C
The key phrase is clearly based upon UNDERWOOD TYPEWRITER COMPANY. All the messages may now be deciphered with ease. The following gives a letter-for-letter decipherment of the first three groups of each message: 14
Message No. 1 C: I J X W X E E C D A C N Q E T . . . . . . . . . . . . . . . . . .
<sup>13 Note that, had we not known (or assumed) the plain-component sequence, we would first have entered these values in a 26×26 square rather than in a single strip for the cipher component, and then we would exploit any manifestations of direct or indirect symmetry present.
<sup>14 The introductory keys for these messages are presumed to have been specified by prearrangement, or indicated by the message number, file time, or some other element of the message externals.
K: R R W K A
OLTCJ
MZDKV
Message No. 3
C: RWKAO
LTCJM
ZDKVU
P: ABOUT
ONEHU
NDRED
K: JXJJP
MLTZK
XECAQ
Message No. 4
C: XJJPM
LTZKX
ECAQZ
P: GUARD
INSUF
FICIE
K: E G I S U
HWZHS
TTZOI
C: GISUH
WZHST
TZOID
Message No. 5
P: NUMER
OUSFL
ASHES
K: B T B J P
AARYY
PVHID
C: TBJPA
ARYYP
VHIDI
Message No. 6
P: THERE
AREAB
OUTSI
K: B|T B J P
AQAAZ
TRXAL
C: TBJPA
QAAZT
Message No. 7
RXALX
ISAMI
XUPHE
P: THERE
f. In the foregoing example the plain component was the normal sequence, so that with the Vigenère method of encipherment the base letter is A. If the plain component is a mixed sequence, the base letter may no longer be A, but in accordance with the principle set forth in subpar. 23b, the frequency of doublets in the cipher text will correspond with the frequency of the base letter as a letter of normal plain text. If a good clue is afforded by the frequency of doublets in the cipher text, the insertion of the corresponding base letter in the plain text will lead to further clues. The solution from there on can be handled along the lines indicated above.
- Solution by means of isomorphs.—a. It was stated in subpar. 23d that in ciphertext autokey systems the production of isomorphs is a frequent phenomenon and that analysis of these isomorphs may yield a quick solution. An example of this sort will now be studied, using as an illustration the following three messages which are suspected of being in a ciphertext autokey system:
Message No. 1
| 0 | _ | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U | S | Y | P | W | T | R | X | D | I | M | L | E | X | R | K | V | D | В | D | D | Q | G | S | U | N | S | F | В | 0 |
| В | E | K | V | В | M | Α | M | M | 0 | T | X | X | В | W | E | N | A | X | M | Q | L | Z | I | X | D | I | X | G | Z |
| P | M | Y | U | C | N | E | v | V | J | L | K | Z | E | K | U | R | C | N | I | F | Q | F | N | N | Y | G | S | Ι | J |
| T | C | V | N | I | X | D | D | Q | Q | E | K | K | L | R | V | R | F | R | F | X | R | 0 | C | S | S | J | T | В | V |
| E | F | A | A | G | Z | R | L | F | D | N | D | S | C | D | M | P | В | В | V | D | E | W | R | R | N | Q | I | С | Н |
| A | T | N | N | В | 0 | U | P | I | T | J | L | X | T | C | V | A | 0 | ٧ | E | Y | J | J | L | K | D | M | L | Е | G |
| N | X | Q | W | Н | U | V | E | V | Y | P | L | Q | G | W | U | P | V | K | U | В | M | M | L | В | 0 | A | E | 0 | T |
| T | N | K | K | U | X | L | 0 | D | L | W | T | Н | C | Z | R | ||||||||||||||
| M | ess | age | e N | o. : | 2 | ||||||||||||||||||||||||
| В | I | I | В | F | G | R | X | L | G | Н | 0 | U | Z | 0 | L | L | Z | N | A | M | Н | C | T | Y | S | C | A | A | T |
| X | R | S | C | T | K | ٧ | В | W | K | 0 | T | G | U | Q | Q | F | J | 0 | C | Y | Y | В | V | K | I | X | D | M | T |
| 17 | m | _ | $\sim$ | _ | 1, | ** | 7.7 | - | _ | - | _ | _ | - | _ | - | ~ | 3.7 | - | - | _ | ^ | 77 | - | 77 | - | - |
XRSCT KVBWK OTGUQ QFJOC YYBVK IXDMT KTTCF KVKRO BOEPL QIGNR IQOVJ YKIPH JOEYM RPEEW HOTJO CRIIX OZETZ NK
Message No. 3
HALOZ JRRVM MHCVB YUHAO EOVAC KZEKU R F RFX YBHAL ZOFHM RSJYL XAGXD MCUNX XLXGZ JPWUI FDBBY PVFZN BJNNB ITMLJ 0 0 S E A ATKPB
<sup>15 If the plain and cipher components had been identical sequences, this fact together with the identity of the base letter could have been determined from the digraphic distribution: one of the rows of the distribution (the row corresponding to the base letter) would reflect an approximation of the normal frequency distribution, i.e., peaks for the letters AEINORST, and blanks or near-blanks for JKQXZ. Furthermore, the reconstruction matrix would have displayed symmetry about the main diagonal (from upper left to lower right); see in this connection subpar. 33e in the next chapter.
9EIAET
b. Frequency distributions are made, based upon the second letters of pairs, as in the preceding example. These distributions are shown in the table in Fig. 27, below. The digraphic LC. is !;~~1~b 1.67, confirming ciphertext autokey with a single-letter introductory key. Nevertheless, the data in each distribution are relatively scanty and it would appear that the solution is going to be a rather difficult matter.
2d letter
| A B C D E F G H I J K L M N 0 P Q R S T U V W X Y Z | N | qi | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 3 | 1 | 1 | 2 | 2 2 | 2 1 | 3 | 1 | 18 | 20 | ||||||||||||||||||
| B | 2 | 1 1 1 | 1 2 1 | 2 | 4 | 3 2 | 3 | 23 | 32 | |||||||||||||||||||
| C | 1 | 1 | 1 | 1 | 2 | 1 1 1 2 1 3 | 1 1 | 17 | 8 | |||||||||||||||||||
| D | 2 | 2 1 | 2 | 1 4 1 | 2 | 1 | 16 | 20 | ||||||||||||||||||||
| E | 1 | 1 1 1 | 4 | 1 2 1 | 1 | 2 2 1 2 | 20 | 20 | ||||||||||||||||||||
| F | 1 1 | 2 | 1 1 | 1 1 | 1 | 1 2 | 2 | 1 | 15 | 6 | ||||||||||||||||||
| G | 1 | 2 | 1 3 | 1 | 1 1 | 3 | 13 | 14 | ||||||||||||||||||||
| H | 4 | 3 | 1 | 1 | 2 | 1 | 12 | 20 | ||||||||||||||||||||
| I | 1 1 | 2 1 | 2 1 | 1 | 1 1 | 2 | 5 | 18 | 26 | |||||||||||||||||||
| J | 1 | 4 | 1 4 1 | 1 | 2 | 2 | 16 | 28 | ||||||||||||||||||||
| K | 1 | 2 | 2 1 | 1 1 | 1 | 1 4 4 | 2 | 20 | 30 | |||||||||||||||||||
| L | 1 1 | 2 1 1 | 1 3 1 | 2 | 2 1 | 1 2 | 3 | 22 | 20 | |||||||||||||||||||
| M | 1 | 1 | 2 | 4 3 | 1 1 1 2 | 1 | 1 | 18 | 22 | |||||||||||||||||||
| N | 2 3 | 1 1 | 2 | 2 | 3 | 1 1 1 | 2 1 | 20 | 20 | |||||||||||||||||||
| 0 | 1 2 3 1 3 1 | 1 | 1 | 1 | 1 4 2 3 | 2 | 26 | 36 | ||||||||||||||||||||
| p | 2 | 1 | 1 | 1 | 2 1 | 2 2 | 12 | 8 | ||||||||||||||||||||
| Q | 1 2 2 | 2 | 1 | 1 | 2 | 1 1 | 13 | 8 | ||||||||||||||||||||
| R | 1 | 4 | 2 | 1 1 | 1 2 1 | 2 3 | 2 | 2 | 22 | 28 | ||||||||||||||||||
| s | 3 | 1 1 | 1 2 | 1 | 1 | 1 1 | 12 | 8 | ||||||||||||||||||||
| T | 1 3 | 1 1 | 2 3 | 1 2 | 1 | 2 | 2 1 1 | 21 | 20 | |||||||||||||||||||
| u | 1 1 | 1 1 | 2 | 2 1 2 1 | 1 | 1 | 1 | 15 | 6 | |||||||||||||||||||
| V | 2 3 | 2 3 1 | 3 3 | 1 1 | 1 | 2 | 1 | 23 | 30 | |||||||||||||||||||
| w | 1 | 2 | 1 | 1 | 2 2 | 9 | 6 | |||||||||||||||||||||
| X | 1 1 | 5 | 2 | 3 1 | 1 | 1 3 1 1 | 2 1 | 23 | 36 | |||||||||||||||||||
| y | 2 | 1 | 1 1 1 1 | 3 | 2 | 1 | 13 | 10 | ||||||||||||||||||||
| z | 3 | 1 2 | 3 2 1 | 2 | 14 | 18 | ||||||||||||||||||||||
| 451 500 |
FIGURE 27
c. Before becoming discouraged too quickly, however, we make a search throughout the text to see if any isomorphs are present. Fortunately, there appear to be several of them. Note the following:
( 1)
Message No. 1 (2)
( 3)
Message No. 2 (4)
Message No. 3 (5)
D B D D Q G S U N S F B 0 B E K . N E V V J L K Z E K U R C N I F . TN K KU XL OD L WT H CZ R]
CR I IX OZ ET ZN K]
C Q V V J L K Z E K U R F R F X
First, it is necessary to delimit the length of the isomorphs. Isomorph (2) shows that the isomorphism begins with the doubled letters; for there is an E before VV in that case and also an E within the isomorph. If the phenomenon included the E, then the letter immediately before the DD in the case of isomorph (1) would have to be an N, to match its homolog, E, in isomorph (2), which it is not. Corroborating data are given by isomorphs (3), (4), and (5) in this respect. Hence, we may take it as established that the isomorphism begins with the doubled letters. As for the end of the isomorphism, the fact that isomorphs (2) and (5) consist of the same set of 10 letters seems to indicate that this number defines the length of the isomorphism. The fact that Message No. 2 ends 2 letters after the last tie-in letter, Z, corroborates this assumption. It is at least certain that the isomorphism does not extend beyond 11 letters because the recurrence of R in isomorph (5) is not matched by the recurrence of R in isomorph (2), nor by the recurrence of T in isomorph (3). Hence it may be assumed that the isomorphic sequence is probably 10 letters in length, possibly 11. But to be on safe ground it is best to proceed on the 10-letter basis.
d. By applying the principles of indirect symmetry to the superimposed isomorphs, partial chains may be constructed, as shown below:
(1-2) D V
QЈ
GL
S K
FUZ
BR
Q U O
(1-3) N D K
G X
SL
W
(1-4) D I
QX
G O
S Z
UE
FNT
ВК
E D
(2-3) V K L X
JUW
Z 0
RKZET
(2-4) V I
JΧ
L O
UN
(3-4) D T K I
UXOE
L Z
These partial chains may be amalgamated into the following sequence:
LODJXBSUN.GW.Q...FVI.RKZET
Noting the J K at an interval of -7, and also W X Z at the same interval, we conclude that a keyword-mixed sequence is involved, and we derive the original sequence as
whereupon we recognize our perennial friend HYDRAULIC and fill in the missing six letters.
e. We now have the cipher component, and the plain component remains to be reconstructed. The simplest and most foolproof solution ordinarily is a reduction to monoalphabetic terms, using the recovered cipher component and the known offset of the cipher text against itself as key. However, the probable word method, if the probable words are at all probable, may be used to good advantage. A good crib to assume for the 10-letter repetition found in Message Nos. 1 and 3 is ARTILLERY (especially since the doublet rate of the distribution in Fig. 27 is $\frac{33}{451}$ =7.3%, which is just right for a base letter of Ap to represent the doublet in the repetition). This single assumption is sufficient to place 7 letters in the plain component, thus:
K: V V J L K Z E K U R C: V V J L K Z E K U R P: A R T I L L E R Y
A . . . E . . . I . . L . . . . . R . T . . . . Y .
These few letters (few, but how beautifully spaced!) are sufficient to suggest that the plain component is in all probability the normal sequence. A few moments' testing proves this to be true. The two components are therefore:
P: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z C: H Y D R A U L I C B E F G J K M N O P Q S T V W X Z
<sup>16 Note that if the LODJX . . . sequence in subpar. d, above, had not been of systematic construction to enable us to analyze its derivation and thus fill in the missing 6 letters, we still could have converted most of the cipher text to monoalphabetic terms, solved the text, and recovered both components.
f. With the two components at hand, the decipherment of the message is a low-order triviality. Since a single-letter introductory key is known to have been used, 17 we decipher the first five groups of Message No. 1 as follows:
K: ? USYP WTRXD IMLEX RKVDB DDQGS
C: USYPW TRXDI MLEXR KVDBD DQGSU...
P: ? PHRF YIVEF IREOF LIGHT ARTIL
The mangled beginning is the result either of garbles, or of specialized keying procedure wherein the last letter of an introductory key was used as the introductory key letter for enciphering the subsequent autokeyed portion of the text (see Fig. 18c in subpar. 21b). If we assume that the IVE before the word FIRE is the ending of the first word of the plain text, and that this word is INTENSIVE, the introductory key word is found to be WICKER. Thus:
K: WICKER TRXDIMLEXRKVDBDDQGS
C: USYPWTRXDIMLEXRKVDBDDQGSU...
P: INTENSIVEFIREOFLIGHTARTIL
The beginnings of the other two messages are recoverable in the same way and are found to be as follows:
K: PROMISERXLGHOUZ C: BIIBFGRXLGHOUZO... P: REQUESTVIGOROUS
K: CHARGEDRRVMMHCV C: HALOZJRRVMMHCVB... P: SECONDBATTALION
- g. The example solved in the foregoing subparagraphs offers an important lesson to the student, insofar as it teaches him that he should not immediately feel discouraged when confronted with a problem presenting only a small quantity of text and therefore affording what seems at first glance to be an insufficient quantity of data for solution. For in this example, while it is true that there are insufficient data for analysis by simple principles of frequency, it turned out that solution was achieved without any recourse to the principles of frequency of occurrence. Here, then, is one of those interesting cases of substitution ciphers of rather complex construction which are solvable without any study whatsoever of frequency distributions. Indeed, it will be found to be true that in more than a few instances the solution of quite complicated cipher systems may be accomplished not by the application of the principles of frequency, but by recourse to inductive and deductive reasoning based upon other considerations, even though the latter may often appear to be very tenuous and to rest upon quite flimsy supports.
- Solution of isologs involving the same pair of unknown primary components.—a. Two messages containing identical plain text encrypted in a ciphertext autokey system with two different single-letter introductory keys may be solved in a manner identical to that described in the last paragraph, since what we really have is a pair of long isomorphs one letter shorter than the length of the messages. Even if the introductory keys are words of different lengths and compositions, if the key usage is similar to that illustrated in Fig. 18c in subpar. 21b the message can be solved very rapidly by reconstructing the primary components, since the cryptographic texts of such messages will be isomorphic after the initial keyword portions.
<sup>17 We know this from (a) statistical evidence of the digraphic distribution at an offset of 1, (b) the indications of the correct plain component emerging from a tentative decipherment of the 10-letter repetition, and (c) the unlikelihood that with three rather short messages a long ciphertext repetition would have manifested itself if the offset were more than 1 letter. We knew that the three messages were autokeyed at the same offset, otherwise the isomorphs would have not appeared among all three messages.
(1) Note the two following superimposed messages, in which isomorphism between the two cryptograms is both obvious and consistent after their 6th letters:
Msg "A": T S B J S K B N L O C F H A Z L W J A M B N F N S Msg "B": B K K M J X Y C X B H R P V O X M U V I Y C R C G Msg "A": M V J R E H F P R X C P C R R E H F M U H R A X C Msg "B": I K U T D P R E T N H E H T T D P R I W P T V N H Msg "A": N F D U B A T F Q R Msg "B": C R S W Y V J R F T
Starting with any pair of superimposed letters (after the 6th pair), the following chains are derived:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 (1) Z O B Y . . . . . . . . . . . . . . . . . .
The foregoing fragments either are part of two 13-letter chains, or they are parts of a complete 26-letter sequence. If the former is the case, then the two 13-letter chains must be (Z O B Y Q F R T J U W M I) and (L X N C H P E D S G A V K); and, a few moments later, noting phenomena associated with keyword-mixed sequences in the two chains, we superimpose them in the diagram 18
Z O B Y Q F R T J U W M I
H P E D S G A V K L X N C
Y Q F R T J U W M I Z O B
from which we speedily obtain the HYDRAULIC . . . XZ sequence. 19
- (2) Only the cipher component has been recovered thus far. If we assume that the plain component is the same as the cipher, the initial key words and the message plain texts are at once deciphered; it will be found that the initial key word for Message "A" is PENCE, and that for Message "B" is LATERAL.20 If the plain component had not been guessed in this case, we could have "deciphered" the message text using an arbitrary plain component (say, the A-Z sequence), resulting in a conversion of the complex cipher text into monoalphabetic terms which can then speedily be solved.
- (3) The foregoing solution affords a clue to the solution of cases in which the texts of two or more messages are not completely identical but are in part identical because they happen to have similar beginnings or endings, or contain nearly similar information or instructions. The progress in such cases is not so rapid as in the case of messages with wholly identical texts because much care must be exercised in blocking out the isomorphic sequences upon which the reconstruction of the primary components will be based.
- b. In the preceding example the autokeyed portions of the texts started with the last letters of the introductory keys. If full autokeying (i.e., the method shown in Fig. 18b), had been employed the solution would hardly be more difficult.
<sup>18 See subpar. 44i on pp. 89-90 of Military Cryptanalytics, Part II.
<sup>19 If the four fragments (1), (2), (3), and (4) had been parts of a complete 26-letter sequence, there would have been only 6 ways to permute them, viz., 1-2-3-4, 1-3-4-3, 1-3-2-4, 1-3-4-2, 1-4-2-3, and 1-4-3-2; therefore the problem would still be solvable without too much effort, even if the cipher component has been a random sequence.
<sup>20 The reason that the cryptographic texts are isomorphic after the initial keyword portions is, of course, that since the text beyond the key word is enciphered autokey fashion by the preceding cipher letter, the letters before the last letter of the key have no effect upon the encipherment at all. Hence two messages having identical plain text cannot be other than isomorphic after the initial keyword portions.
SECRET
(1) In order to illustrate such a case, let the same plain texts used in the preceding example be enciphered by introductory key words of the same lengths but different compositions: PENCE and LATER. Thus:
Message "A"
| P: | P E | Q | U | E | S | T | Ι | N | F | 0 | Ŕ | M | A | T | I | 0 | N | 0 | F | S | I | T | U | A | T | I | 0 | N | I |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P: | D W N F P C |
'I | F | T | E | E | N | T | Н | I | N | F | A | N | T | R | Y | S | E | C | T | 0 | R | A | T | 0 | N | C | E |
| M | ess | age | "B | " | |||||||||||||||||||||||||
| P: | L A R E B K |
Q | U | E | S | T | I | N | F | 0 | R | M | A | T | I | 0 | N | 0 | F | S | I | T | U | A | T | I | 0 | N | I |
(2) Now let the cipher texts be superimposed and isomorphisms be sought. They are shown underlined below:
\begin{array}{cccccccccccccccccccccccccccccccccccc
It will be noted that the intervals between identical vertical pairs show a constant factor of 5, indicating that the messages have been enciphered with 5-letter introductory key words.
(3) The vertical pairs beyond the first five letters of the messages are now distributed in a reconstruction matrix according to their position based upon this interval of 5, similar to the treatment of vertical pairs in periodic-cipher isologs arising from the use of repeating keys of the same lengths.21 This is shown below:
| Ø | A | В | C | D | E | F | G | Н | I | J | K | L | M | N | 0 | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | P | W | N | Н | Т | Y | S | R | L | |||||||||||||||||
| 2 | R | D | U | Н | В | E | G | 0 | ł | |||||||||||||||||
| 3 | В | G | Q | S | Т | Н | E | D | ||||||||||||||||||
| 4 | L | Ε | D | В | T | U | Z | Н | Y | |||||||||||||||||
| 5 | A | Q | Н | C | E | K | X | M |
From the values in this matrix the original cipher component, the HYDRAULIC . . . XZ sequence, may quickly be recovered, because the Ø line may be included in the chaining.
(b) (1)
(b) (3) - 18 USC 798
(b) (3) - 50 USC 3024(i)
(b) (3) - P.L. 86 - 36
<sup>21 Cf. subpar. 60f, Military Cryptanalytics, Part II.
| 2 | i | SECRET | |
|---|---|---|---|
| • • . |
61 -CEONET 206-687 O - 77 - 5
(b) (1)
(b) (3)-18 USC 798 (b) (3)-50 USC 3024(i)
(b) (3)-P.L. 86-36
| - WOULD TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO THE TOTAL TO | |
|---|---|
CECDET
62
(b) (1)
(b) (3) -18 USC 798 (b) (3) -50 USC 3024(i) (b) (3) -P.L. 86-36
| ; | |||
|---|---|---|---|
| ı | |||
| • | |||
| 63 | (1.) (1.) | SECRET | |
| (L) (d) | |||
| (b)(3)-18 USC 798 | |||
| == | (b) (1) (b) (3) -18 USC 798 (b) (3) -50 USC 3024(i) |
||
| . ==: | - | (~),(0), 00 000 004 1(1) |
(b)(3)-P.L. 86-36
CECNET

_CECRET_
64
(b) (1)
(b) (3) -18 USC 798
(b) (3) - 50 USC 3024(i)
(b)(3)-P.L. 86-36
| OEGRET. | |
|---|---|
| ••• |

SECRET
(b) (1)
(b)(3)-18 USC 798
(b)(3)-50 USC 3024(i)
(b)(3)-P.L. 86-36
| • | |
|---|---|
(b) (3) -18 USC 798 (b) (3) -50 USC 3024(i) (b) (3) -P.L. 86-36

| ; | -CEORET |
|---|---|
(b) (1)
(b) (3) -18 USC 798 (b) (3) -50 USC 3024(i)
(b)(3)-P.L. 86-36
CEONET
- Further remarks on ciphertext autokey systems.—a. All of the discussion on ciphertext autokey systems thus far has been limited to alphabetical systems employing sliding primary components (or the equivalent form of a square table). There is no reason, of course, why a set of 26 unrelated random sequences in a table such as that in Fig. 33, below, could not be used for the cipher alphabets. In such
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z ATOKZBLRXSPWNAQCEIGDJF SBACDEHFIJKTLMOUVYGZNPQ CYQRTVWLADKOMJUBGEPHSCZINXF D Z S A E D C B I F G J H L K M R U O Q V P T N W Y X ESLWEMZVXGAFNQUKDOPITJBRHCY G P O C I X L U R N D Y Z H W B J S Q F K V M E T A G W A H X J E Z B N I K P V R O G S Y D U L C F M Q T H G T D X A I H P J O B W K C V F Z L Q E R Y N S U M IAJDSKQOIVTZEFHGYUNLPMBXWCR J G H O N M T P R Q S V Z U X Y W I C A K E L B D F K V Q P N O H U W D I Z Y C G K R F B E J A L T M S X EWOAMNFLHQGCUJTBYPZKXISRDV D H B M K G X U Z T S W Q Y V O R P F E A N C J I L NDWPKJVIUQHZCTXBLEGNYRSMFAO OSGUENTCXOWFQDRLJZMAPBVHIYK P X C S H D E O K F P Y A Q J N U B T G I M W Z R V L N V A R M Y O F T H E U S Z J X D P C W G Q I B K L OZPLGVJRKYTFUIWXHASDMCNEQB STOJYLFXNGWHVCMIRBSEKUPDZQA ZXQLYIOVBPESNHJWMDGFCKAUTR EYBFSJMUDQCLZWTIPAVNKHRGOX V X P U C O T Y A W V S F D L I E B H K N R J Q Z G M WEVDTUFOYHMLSIQNJCPGBZAXKWR XMVKBQWUGLOSTECHNZFRIDAYJPX YWJLVGRCQMPSOEXTKIAZDNBUHYF ZTBREMXZPVQYUOGAIKLFSWHDCNJ
FIGURE 33
cases, the general methods treated in par. 22 still apply, with necessary modifications, as also do the methods in pars. 23 and 24, except that it is obvious that (a) there will be no determinable base letter, and (b) there will be no causal isomorphs. For that matter, even with a matrix such as that of Fig. 34 below, in which the key letters are designated by arbitrary letters to the left of the square (instead of
Plain HYDRAULICBEFGJKMNOPQSTVWXZ AHYDRAULICBEFGJKMNOPQST BYDRAULICBEFGJKMNOPQSTVWX CDRAULICBEFGJKMNOPQSTVWXZHY DRAULICBEFGJKMNOPQSTVWXZHYD AULICBEFGJKMNOPQSTVWXZHYDR FULICBEFGJK M N O P Q S T V W X Z H Y D R A G L I C B E F G J K M N O P Q S T V W X Z H Y D R A U HICBEFGJKMNOPQSTVWXZHYDRAU ICBEFGJKMNOPQSTVWXZHYDRAULI J B E F G J K M N O P Q S T V W X Z H Y D R A U L I C K E F G J K M N O P Q S T V W X Z H Y D R A U L I C B LFGJKMNOPQSTVWXZHYDRAULICBE MGJKMNOPQSTVWXZHYDRAULICBEF Key N J K M N O P Q S T V W X Z H Y D R A U L I C B E F G O K M N O P Q S T V W X Z H Y D R A U L I C B E F G P M N O P Q S T W W X Z H Y D R A U L I C B E F G J K QNOPQSTVWXZHYDRAULICBEFGJKM O P Q S T V W X Z H Y D R A U L I C B E F G J K M N PQSTVWXZHYDRAULICBEFGJKMNO QSTVWXZHYDRAULICBEFGJKMNOP USTVWXZHYDRAULICBEFGJKMNOP TVWXZHYDRAULICBEFGJKMNOPQ V W X Z H Y D R A U L I C B E F G J K M N O P Q S W X Z H Y D R A U L I C B E F G J K M N O P Q S T V YXZHYDRAULICBEFGJKMNOPQSTVW ZZHYDRAULICBEFGJKMNOPQSTVWX
FIGURE 34
the letters in a column under a particular plaintext letter—the base letter), there is likewise no determinable base letter and no causal isomorphs can be produced, as can be shown by the following isologous message beginnings:
Message "A"
K: XI P M Q Q P P Z F G T R I R Z N D P Q L J Y M L L H X Q W G P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . . C: P M Q Q P P Z F G T R I R Z N D P Q L J Y M L L H X Q W G P
Message "B"
K: Y Q N S T T V U L P A E S J O U B N O A D T E X P A O E F T P: T H I R D R E G I M E N T C O M M A N D P O S T M O V I N G . . . C: Q N S T T V U L P A E S J O U B N O A D T E X P A O E F T U
The ciphertext doublets are the result of chance. Note in this example that, since the plain and cipher components are identical sequences, one of the distributions of the letters immediately following a particular cipher letter (in this case, $A_c$ ) will fit the normal, since the plaintext letters enciphered by this key letter will be self-enciphered; the distributions of the letters following the other cipher letters will of course be monoalphabetic.
SECRET.
- b. The general principles of ciphertext autokeying apply equally well to digital systems, and for that matter to Baudot systems. The modulus in digital systems is the usual mod-10 arithmetic, so that in effect the cipher component is a known sequence—thus a reduction to monoalphabetic terms suggests itself at once, if not sooner.
- c. As an example, let us study the following message, suspected of having been enciphered in a ciphertext autokey system with the additive method of encipherment (P+K=C).27
1 3 7 5 6
92001
94093
2 2 1 2 3
69720
3 9 4 9 8
79929
30476
58112
49369
28072
48301
90074
1 2 9 4 3
50529
3 1 5 8 9
52814
74516
40544
11682
05793
10649
7 1 9 3 2
40506
19689
99661
If a single-digit introductory key has been used, the cipher text is offset against itself at an interval of 1 and a decipherment obtained, the beginning of which is shown below:28
K: 1563 59200 11375 69409 30515
C: 15635 92001 13756 94093 05151 . . . P: 4172 43801 02481 35694 75646
The I.C. of the entire deciphered message is 0.99, so the length of the introductory key was probably not 1. The cipher text is then offset against itself at intervals of 2, 3, 4 . . ., up to an interval of 9: the I.C.'s obtained from the resulting decipherments are all unsatisfactory, as may be seen from the following table:
| Offset | I.C. | Offset | I.C. | Offset | I.C. |
|---|---|---|---|---|---|
| 1 | 0. 99 | 4 | 0. 97 | 7 | 0. 99 |
| 2 | 1.02 | 5 | 0. 96 | 8 | 0. 98 |
| 3 | 1.02 | 6 | 0. 96 | 9 | 0. 97 |
| ļ | 1 |
26 If other than mod-10 arithmetic is used, say an arbitrary conversion-square encipherment with a square such as the following,
| riani | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| 0 | 3 | 1 | 6 | 7 | 5 | 8 | 2 | 4 | 9 | 0 | |
| Key | 1 | 1 | 2 | 3 | 5 | 4 | 6 | 8 | 9 | 0 | 7 |
| 2 | 6 | 4 | 0 | 2 | 8 | 1 | 5 | 3 | 7 | 9 | |
| 3 | 7 | 3 | 2 | 9 | 0 | 5 | 6 | 1 | 8 | 4 | |
| 4 | 5 | 8 | 4 | 0 | 9 | 2 | 3 | 7 | 1 | 6 | |
| 5 | 8 | 5 | 1 | 6 | 7 | 9 | 0 | 2 | 4 | 3 | |
| 6 | 2 | 9 | 8 | 1 | 3 | 7 | 4 | 0 | 6 | 5 | |
| 7 | 4 | 6 | 9 | 8 | 2 | 0 | 7 | 5 | 3 | 1 | |
| 8 | 9 | 0 | 7 | 3 | 6 | 4 | 1 | 8 | 5 | 2 | |
| 9 | 0 | 7 | 5 | 4 | 1 | 3 | 9 | 6 | 2 | 8 | |
the problem must be solved as a general case of ciphertext autokey as treated earlier in this chapter. (The conversion square shown here is a Latin square, with ten unique digits in each of the rows and in each of the columns; other conversion squares may have columns containing repeated digits.)
- 27 As regards the effect of the use of different encipherment conventions, see subpars. 35g and h (on pp. 117-120).
- 28 We have assumed that the enciphering procedure was the additive method (i.e., wherein P+K=C); see also the remarks in subpar. 35h in the next chapter if subtractive or minuend methods had been involved.
d. When an offset of 10 is tried, the I.C. of the deciphered text jumps to 1.52 and a long repetition is in evidence, revealing that 10 is the length of the introductory key. The decipherment and its appertaining frequency distribution are shown below:
K:
1 5 6 3 5
92001
13756
9 4 0 9 3
0 5 1 5 1
C: 15635
92001
1 3 7 5 6
40094
9 2 4 0 5
0 8 1 2 1
02092
56001
30476
K: 0 5 1 5 1
40094
2 2 1 2 3
69720
C: 2 2 1 2 3
7 6
69720
3 9 4 9 8
79929
58112
4
P: 27072
482
47607
09022
10209
K: 79929
58112
76111
49369
28072
C: 76111
4 9
3 6 9
28072
48301
90074
45548
P: 07292
9 1 2 5 7
52961
09042
72002
1 2 9 4 3
K: 90074
45548
40544
3 1 5 2 9
C: 40544
3 1 5 2 9
1 2 9 4 3
50569
52814
P: 5 0 5 7 0
96081
7 2 4 0 9
29040
40971
K: 52814
7 4 5 5 6
7 1 9 3 2
40546
11682
0 5 7 3 3
C: 7 1 9 3 2
40546
11682
0 5 7 3 3
10649
25635
P: 29128
76
090
40750
65297
09067
K: 10649
25635
C: 19689
99601
P: 0 9 0 4 0
74076
|| || || || || || || || || || || || ||
From here on the solution of the intermediate text is a simple matter; monome-dinome characteristics are observed in the preliminary examination, and recovery of the plain text and of the enciphering matrix quickly follow.29
<sup>29 The analysis of the intermediate text is given in par. 77 of Military Cryptanalytics, Part I.