Minsky and Papert
from Perceptrons: An Introduction to Computational Geometry
Prologue: A View from 1988
This book is about perceptrons—the simplest learning machines. However, our deeper purpose is to gain more general insights into the interconnected subjects of parallel computation, pattern recognition, knowledge representation, and learning. It is only because one cannot think productively about such matters without studying specific examples that we focus on theories of perceptrons.
In preparing this edition we were tempted to " bring those theories up to date." But when we found that little of significance had changed since 1969, when the book was first published, we concluded that it would be more useful to keep the original text (with its corrections of 1972) and add an epilogue, so that the book could still be read in its original form. One reason why progress has been so slow in this field is that researchers unfamiliar with its history have continued to make many of the same mistakes that others have made before them. Some readers may be shocked to hear it said that little of significance has happened in this field. Have not perceptron-like networks—under the new name connectionism become a major subject of discussion at gatherings of psychologists and computer scientists? Has not there been a " connectionist revolution?" Certainly yes, in that there is a great deal of interest and discussion. Possibly yes, in the sense that discoveries have been made that may, in time, turn out to be of fundamental importance. But certainly no, in that there has been little clear-cut change in the conceptual basis of the field.,The issues that give rise to excitement today seem much the same as those that were responsible for previous rounds of excitement. The issues that were then obscure remain obscure today because no one yet knows how to tell which of the present discoveries are fundamental and which are superficial. Our position remains what it was when we wrote the book: We believe this realm of work to be immensely important and rich, but we expect its growth to require a degree of critical analysis that its more romantic advocates have always been reluctant to pursue—perhaps because the spirit of connectionism seems itself to go somewhat against the grain of analytic rigor.
In the next few pages we will try to portray recent events in the field of parallel-network learning machines as taking place within the historical context of a war between antagonistic tendencies called symbolist and connectionist. Many of the participants in this history see themselves as divided on the question of strategies for
thinking—a division that now seems to pervade our culture, engaging not only those interested in building models of mental functions but also writers, educators, therapists, and philosophers. Too many people too often speak as though the strategies of thought fall naturally into two groups whose attributes seem diametrically opposed in character:
symbolic logical serial discrete localized hierarchical left-brained connectionist analogical parallel continuous distributed heterarchical right-brained
This broad division makes no sense to us, because these attributes are largely independent of one another; for example, the very same system could combine symbolic, analogical, serial, continuous, and localized aspects. Nor do many of those pairs imply clear opposites; at best they merely indicate some possible extremes among some wider range of possibilities. And although many good theories begin by making distinctions, we feel that in subjects as broad as these there is less to be gained from sharpening boundaries than from seeking useful intermediates.
The 1940s: Neural Networks
The 1940s saw the emergence of the simple yet powerful concept that the natural components of mind-like machines were simple abstractions based on the behavior of biological nerve cells, and that such machines could be built by interconnecting such elements. In their 1943 manifesto " A Logical Calculus of the Ideas Immanent in Nervous Activity," Warren McCulloch and Walter Pitts presented the first sophisticated discussion of " neuro-logical networks," in which they combined new ideas about finite-state machines, linear threshold decision elements, and logical representations of various forms of behavior and memory. In 1947 they published a second monumental essay, " How We Know Universals," which described network architectures capable, in principle, of recognizing spatial patterns in a manner invariant under groups of geometric transformations.
From such ideas emerged the intellectual movement called cybernetics, which attempted to combine many concepts from biology, psychology, engineering, and mathematics. The cybernetics era produced a flood of architectural schemes for making neural networks recognize, track, memorize, and perform many other useful functions. The decade ended with the publication of Donald Hebb's book The Organization of Behavior, the first attempt to base a large-scale theory of psychology on conjectures about neural networks. The central idea of Hebb's book was that such networks might learn by constructing internal representations of concepts in the form of what Hebb called " cell-assemblies" subfamilies of neurons that would learn to support one another's activities. There had been earlier attempts to explain psychology in terms of " connections" or " associations," but (perhaps because those connections were merely between symbols or ideas rather than between mechanisms) those theories seemed then too insubstantial to be taken seriously by theorists seeking models for mental mechanisms. Even after Hebb's proposal, it was years before research in artificial intelligence found suitably convincing ways to make symbolic concepts seem concrete.
The 1950s: Learning in Neural Networks
The cybernetics era opened up the prospect of making mind-like machines. The earliest workers in that field sought specific architectures that could perform specific functions. However, in view of the fact that animals can learn to do many things they aren't built to do, the goal soon changed to making machines that could learn. Now, the concept of learning is ill defined, because there is no clear-cut boundary between the simplest forms of memory and complex procedures for making predictions and generalizations about things never seen. Most of the early experiments were based on the idea of " reinforcing" actions that had been successful in the past—a concept already popular in behavioristic psychology. In order for reinforcement to be applied to a system, the system must be capable of generating a sufficient variety of actions from which to choose and the system needs some criterion of relative success. These are also the prerequisites for the " hill-climbing" machines that we discuss in section 11.6 and in the epilogue.
Perhaps the first reinforcement-based network learning system was a machine built by Minsky in 1951. It consisted of forty electronic
units interconnected by a network of links, each of which had an adjustable probability of receiving activation signals and then transmitting them to other units. It learned by means of a reinforcement process in which each positive or negative judgment about the machine's behavior was translated into a small change (of corresponding magnitude and sign) in the probabilities associated with whichever connections had recently transmitted signals. The 1950s saw many other systems that exploited simple forms of learning, and this led to a professional specialty called adaptive control.
Today, people often speak of neural networks as offering a promise of machines that do not need to be programmed. But speaking of those old machines in such a way stands history on its head, since the concept of programming had barely appeared at that time. When modern serial computers finally arrived, it became a great deal easier to experiment with learning schemes and " selforganizing systems.'' However, the availability of computers also opened up other avenues of research into learning. Perhaps the most notable example of this was Arthur Samuel's research on programming computers to learn to play checkers. (See Bibliographic Notes.) Using a success-based reward system, Samuel's 1959 and 1967 programs attained masterly levels of performance. In developing those procedures, Samuel encountered and described two fundamental questions:
Credit assignment. Given some existing ingredients, how does one decide how much to credit each of them for each of the machine's accomplishments? In Samuel's machine, the weights are assigned by correlation with success.
Inventing novel predicates. If the existing ingredients are inadequate, how does one invent new ones? Samuel's machine tests products of some preexisting terms.
Most researchers tried to bypass these questions, either by ignoring them or by using brute force or by trying to discover powerful and generally applicable methods. Few researchers tried to use them as guides to thoughtful research. We do not believe that any completely general solution to them can exist, and we argue in our epilogue that awareness of these issues should lead to a model of mind that can accumulate a multiplicity of specialized methods.
By the end of the 1950s, the field of neural-network research had become virtually dormant. In part this was because there had not been many important discoveries for a long time. But it was also partly because important advances in artificial intelligence had been made through the use of new kinds of models based on serial processing of symbolic expressions. New landmarks appeared in the form of working computer programs that solved respectably difficult problems. In the wake of these accomplishments, theories based on connections among symbols suddenly seemed more satisfactory. And although we and some others maintained allegiances to both approaches, intellectual battle lines began to form along such conceptual fronts as parallel versus serial processing, learning versus programming, and emergence versus analytic description.
The 1960s: Connectionists and Symbolists
Interest in connectionist networks revived dramatically in 1962 with the publication of Frank Rosenblatt's book Principles of Neurodynamicsy in which he defined the machines he named perceptrons and proved many theories about them. (See Bibliographic Notes.) The basic idea was so simply and clearly defined that it was feasible to prove an amazing theorem (theorem 11.1 below) which stated that a perceptron would learn to do anything that it was possible to program it to do. And the connectionists of the 1960s were indeed able to make perceptrons learn to do certain things but not other things. Usually, when a failure occurred, neither prolonging the training experiments nor building larger machines helped. All perceptrons would fail to learn to do those things, and once again the work in this field stalled.
Arthur Samuel's two questions can help us see why perceptrons worked as well as they did. First, Rosenblatt's credit-assignment method turned out to be as effective as any such method could be. When the answer is obtained, in effect, by adding up the contributions of many processes that have no significant interactions among themselves, then the best one can do is reward them in proportion to how much each of them contributed. (Actually, with perceptrons, one never rewards success; one only punishes failure.) And Rosenblatt offered the simplest possible approach to the problem of inventing new parts: You don't have to invent new parts if
enough parts are provided from the start. Once it became clear that these tactics would work in certain circumstances but not in others, most workers searched for methods that worked in general. However, in our book we turned in a different direction. Instead of trying to find a method that would work in every possible situation, we sought to find ways to understand why the particular method used in the perceptron would succeed in some situations but not in others. It turned out that perceptrons could usually solve the types of problems that we characterize (in section 0.8) as being of low "order." With those problems, one can indeed sometimes get by with making ingredients at random and then selecting the ones that work. However, problems of higher "orders" require too many such ingredients for this to be feasible.
This style of analysis was the first to show that there are fundamental limitations on the kinds of patterns that perceptrons can ever learn to recognize. How did the scientists involved with such matters react to this? One popular version is that the publication of our book so discouraged research on learning in network machines that a promising line of research was interrupted. Our version is that progress had already come to a virtual halt because of the lack of adequate basic theories, and the lessons in this book provided the field with new momentum—albeit, paradoxically, by redirecting its immediate concerns. To understand the situation, one must recall that by the mid 1960s there had been a great many experiments with perceptrons, but no one had been able to explain why they were able to learn to recognize certain kinds of patterns and not others. Was this in the nature of the learning procedures? Did it depend on the sequences in which the patterns were presented? Were the machines simply too small in capacity?
What we discovered was that the traditional analysis of learning machines—and of perceptrons in particular—had looked in the wrong direction. Most theorists had tried to focus only on the mathematical structure of what was common to all learning, and the theories to which this had led were too general and too weak to explain which patterns perceptrons could learn to recognize. As our analysis in chapter 2 shows, this actually had nothing to with learning at all; it had to do with the relationships between the perceptron's architecture and the characters of the problems that were being presented to it. The trouble appeared when perceptrons
had no way to represent the knowledge required for solving certain problems. The moral was that one simply cannot learn enough by studying learning by itself; one also has to understand the nature of what one wants to learn. This can be expressed as a principle that applies not only to perceptrons but to every sort of learning machine: No machine can learn to recognize X unless it possesses, at least potentially, some scheme for representing» X.
The 1970s: Representation of Knowledge
Why have so few discoveries about network machines been made since the work of Rosenblatt? It has sometimes been suggested that the " pessimism" of our book was responsible for the fact that connectionism was in a relative eclipse until recent research broke through the limitations that we had purported to establish. Indeed, this book has been described as having been intended to demonstrate that perceptrons (and all other network machines) are too limited to deserve further attention. Certainly many of the best researchers turned away from network machines for quite some time, but present-day connectionists who regard that as regrettable have failed to understand the place at which they stand in history. As we said earlier, it seems to us that the effect of Perceptrons was not simply to interrupt a healthy line of research. That redirection of concern was no arbitrary diversion; it was a necessary interlude. To make further progress, connectionists would have to take time off and develop adequate ideas about the representation of knowledge. In the epilogue we shall explain why that was a prerequisite for understanding more complex types of network machines.
In any case, the 1970s became the golden age of a new field of research into the representation of knowledge. And it was not only connectionist learning that was placed on hold; it also happened to research on learning in the field of artificial intelligence. For example, although Patrick Winston's 1970 doctoral thesis (see " Learning Structural Definitions from Examples," in The Psychology of Computer Vision, ed. P. H. Winston [McGraw-Hill, 1975]) was clearly a major advance, the next decade of A1 research saw surprisingly little attention to that subject.
In several other related fields, many researchers set aside their interest in the study of learning in favor of examining the representation of knowledge in many different contexts and forms. The
result was the very rapid development of many new and powerful ideas—among them frames, conceptual dependency, production systems, word-expert parsers, relational databases, K-lines, scripts, nonmonotonic logic, semantic networks, analogy generators, cooperative processes, and planning procedures. These ideas about the analysis of knowledge and its embodiments, in turn, had strong effects not only in the heart of artificial intelligence but also in many areas of psychology, brain science, and applied expert systems. Consequently, although not all of them recognize this, a good deal of what young researchers do today is based on what was learned about the representation of knowledge since Perceptrons first appeared. As was asserted above, their not knowing that history often leads them to repeat mistakes of the past. For example, many contemporary experimenters assume that, because the perceptron networks discussed in this book are not exactly the same as those in use today, these theorems no longer apply. Yet, as we will show in our epilogue, most of the lessons of the theorems still apply.
The 1980s: The Revival of Learning Machines
What could account for the recent resurgence of interest in network machines? What turned the tide in the battle between the connectionists and the symbolists? Was it that symbolic A1 had run out of steam? Was it the important new ideas in connectionism? Was it the prospect of new, massively parallel hardware? Or did the new interest reflect a cultural turn toward holism?
Whatever the answer, a more important question is: Are there inherent incompatibilities between those connectionist and symbolist views? The answer to that depends on the extent to which one regards each separate connectionist scheme as a self-standing system. If one were to ask whether any particular, homogeneous network could serve as a model for a brain, the answer (we claim) would be, clearly. No. But if we consider each such network as a possible model for a part of a brain, then those two overviews are complementary.
This is why we see no reason to choose sides. We expect a great many new ideas to emerge from the study of symbol-based theories and experiments. And we expect the future of network-based learning machines to be rich beyond imagining. As we say in section 0.3, the solemn experts who complained most about the " exaggerated claims" of the cybernetics enthusiasts were, on balance, in the wrong. It is just as clear to us today as it was 20 years ago that the marvelous abilities of the human brain must emerge from the parallel activity of vast assemblies of interconnected nerve cells. But, as we explain in our epilogue, the marvelous powers of the brain emerge not from any single, uniformly structured connectionist network but from highly evolved arrangements of smaller, specialized networks which are interconnected in very specific ways.
The movement of research interest between the poles of connectionist learning and symbolic reasoning may provide a fascinating subject for the sociology of science, but workers in those fields must understand that these poles are artificial simplifications. It can be most revealing to study neural nets in their purest forms, or to do the same with elegant theories about formal reasoning. Such isolated studies often help in the disentangling of different types of mechanisms, insights, and principles. But it never makes any sense to choose either of those two views as one's only model of the mind. Both are partial and manifestly useful views of a reality of which science is still far from a comprehensive understanding.
0
0.0 Readers
In writing this we had in mind three kinds of readers. First, there are many new results that will interest specialists concerned with ''pattern recognition," "learning machines," and "threshold logic." Second, some people will enjoy reading it as an essay in abstract mathematics; it may appeal especially to those who would like to see geometry return to topology and algebra. We ourselves share both these interests. But we would not have carried the work as far as we have, nor presented it in the way we shall, if it were not for a different, less clearly defined, set of interests.
The goal of this study is to reach a deeper understanding of some concepts we believe are crucial to the general theory of computation. We will study in great detail a class of computations that make decisions by weighing evidence. Certainly, this problem is of great interest in itself, but our real hope is that understanding of its mathematical structure will prepare us eventually to go further into the almost unexplored theory of parallel computers.
The people we want most to speak to are interested in that general theory of computation. We hope this includes psychologists and biologists who would like to know how the brain computes thoughts and how the genetic program computes organisms. We do not pretend to give answers to such questions—nor even to propose that the simple structures we shall use should be taken as "models" for such processes. Our aim—we are not sure whether it is more modest or more ambitious—is to illustrate how such a theory might begin, and what strategies of research could lead to it.
It is for this third class of readers that we have written this introduction. It may help those who do not have an immediate involvement with it to see that the theory of pattern recognition might be worth studying for other reasons. At the same time we will set out a simplified version of the theory to help readers who have not had the mathematical training that would make the later chapters easy to read. The rest of the book is self-contained and anyone who hates introductions may go directly to Chapter 1.
0.1 Real, Abstract, and Mythological Computers
We know shamefully little about our computers and their computations. This seems paradoxical because, physically and logically.
computers are so lucidly transparent in their principles of operation. Yet even a school boy can ask questions about them that today's "computer science" cannot answer. We know' very little, for instance, about how much computation a job should require.
As an example, consider one of the most frequently performed computations: solving a set of linear equations. This is important in virtually every kind of scientific work. There are a variety of standard programs for it, which are composed of additions, multiplications, and divisions. One would suppose that such a simple and important subject, long studied by mathe.maticians, would by now' be thoroughly understood. But we ask, How' many arithmetic steps are absolutely required? How' does this depend on the amount of computer memory? How' much time can we save if we have two (or n) identical computers? Every computer scientist "knows" that this computation requires something of the order of multiplications for n equations, but even if this be true no one knows—at this writing—how to begin to prove it.
Neither the outsider nor the computation specialist seems to recognize how primitive and how empirical is our present state of understanding of such matters. We do not know how' much the speed of computations can be increased, in general, by using "parallel" as opposed to "serial"—or "analog" as opposed to "digital"—machines. We have no theory of the situations in which "associative" memories will justify their higher cost as compared to "addressed" memories. There is a great deal of folklore about this sort of contrast, but much of this folklore is mere superstition; in the cases we have studied carefully, the common beliefs turn out to be not merely " unproved"; they are often drastically wrong.
The immaturity show n by our inability to answer questions of this kind is exhibited even in the language used to formulate the questions. Word pairs such as "parallel" vs. "serial:" "local" vs. "global," and "digital" vs. "analog" are used as if they referred to well-defined technical concepts. Even when this is true, the technical meaning varies from user to user and context to context. But usually they are treated so loosely that the species of computing machine defined by them belongs to mythology rather than science.
Now we do not mean to suggest that these are mere pseudoproblems that arise from sloppy use of language. This is not a book of "therapeutic semantics" ! For there is much content in these intuitive ideas and distinctions. The problem is how to capture it in a clear, sharp theory.
0.2 Mathematical Strategy
We are not convinced that the time is ripe to attempt a very general theory broad enough to encompass the concepts we have mentioned and others like them. Good theories rarely develop outside the context of a background of well-understood real problems and special cases. Without such a foundation, one gets either the vacuous generality of a theory with more definitions than theorems—or a mathematically elegant theory with no application to reality.
Accordingly, our best course would seem to be to strive for a very thorough understanding of well-chosen particular situations in which these concepts are involved.
We have chosen in fact to explore the properties of the simplest machines we could find that have a clear claim to be "parallel" for they have no loops or feedback paths—yet can perform computations that are nontrivial, both in practical and in mathematical respects.
Before we proceed into details, we would like to reassure nonmathematicians who might be frightened by what they have glimpsed in the pages ahead. The mathematical methods used are rather diverse, but they seldom require advanced knowledge. We explain most of that which goes beyond elementary algebra and geometry. Where this was not practical, we have marked as optional those sections we feel might demand from most readers more mathematical effort than is warranted by the topic's role in the whole structure. Our theory is more like a tree with many branches than like a narrow high tower of blocks; in many cases one can skip, if trouble is encountered, to the beginning of the following chapter.
The reader of most modern mathematical texts is made to work unduly hard by the authors' tendency to cover over the intellectual tracks that lead to the discovery of the theorems. We have
tried to leave visible the lines of progress. We should have liked to go further and leave traces of all the false tracks we followed; unfortunately there were too many! Nevertheless we have occasionally left an earlier proof even when we later found a "better'' one. Our aim is not so much to prove theorems as to give insight into methods and to encourage research. We hope this will be read not as a chain of logical deductions but as a mathematical novel where characters appear, reappear, and develop.
0.3 Cybernetics and Romanticism
The machines we will study are abstract versions of a class of devices known under various names; we have agreed to use the name "perceptron" in recognition of the pioneer work of Frank Rosenblatt. Perceptrons make decisions—determine whether or not an event fits a certain "pattern"—by adding up evidence obtained from many small experiments. This clear and simple concept is important because most, and perhaps all, more complicated machines for making decisions share a little of this character. Until we understand it very thoroughly, we can expect to have trouble with more advanced ideas. In fact, we feel that the critical advances in many branches of science and mathematics began with good formulations of the "linear" systems, and these machines are our candidate for beginning the study of "parallel machines" in general.
Our discussion will include some rather sharp criticisms of earlier work in this area. Perceptrons have been widely publicized as "pattern recognition" or "learning" machines and as such have been discussed in a large number of books, journal articles, and voluminous "reports." Most of this writing (some exceptions are mentioned in our bibliography) is without scientific value and we will not usually refer by name to the works we criticize. The sciences of computation and cybernetics began, and it seems quite rightly so, with a certain flourish of romanticism. They were laden with attractive and exciting new ideas which have already borne rich fruit. Heavy demands of rigor and caution could have held this development to a much slower pace; only the future could tell which directions were to be the best. We feel, in fact, that the solemn experts who most complained about the "exaggerated claims" of the cybernetic enthusiasts were, in the balance, much more in the wrong. But now the time has come for maturity, and this requires us to match our speculative enterprise with equally imaginative standards of criticism.
0.4 Parallel Computation
The simplest concept of parallel computation is represented by the diagram in Figure 0.1. The figure shows how one might compute a function \p(^) in two stages. First we compute independently of one another a set of functions ip(X), <p2*(X* ..., (Pn(X) and then combine the results by means of a function Q of a? arguments to obtain the value of yp.
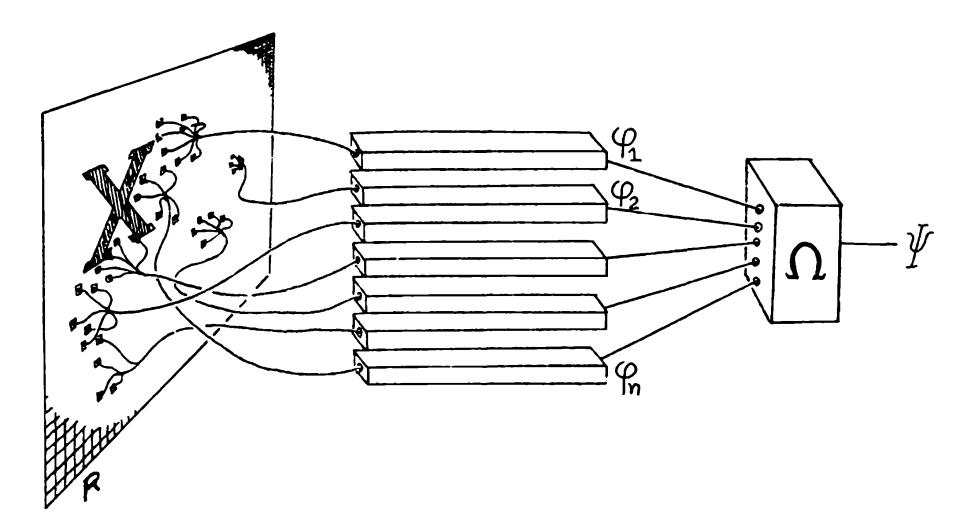
To make the definition meaningful—or, rather, productive—one needs to place some restrictions on the function i2 and the set ^ of functions (p,(P2*.* __ If we do not make restrictions,we do not get a theory: any computation \p could be represented as a parallel computation in various trivial ways, for example, by making one of the (f's be \p and letting Q do nothing but transmit its result. We will consider a variety of restrictions, but first we will give a few concrete examples of the kinds of functions we might want \p to be.
0.5 Some Geometric Patterns; Predicates
Let R be the ordinary two-dimensional Euclidean plane and let X be a geometric figure drawn on R. X could be a circle, or a pair of circles, or a black-and-white sketch of a face. In general we will think of a figure X as simply a subset of the points of R (that is, the black points).
Let \p{X) be a function (of figures X on R) that can have but two values. We usually think of the two values of ^ as 0 and 1. But by taking them to be fal se and t rue we can think of yp{X) as a predicate, that is, a variable statement whose truth or falsity depends on the choice of X. We now give a few examples of predicates that will be of particular interest in the sequel.
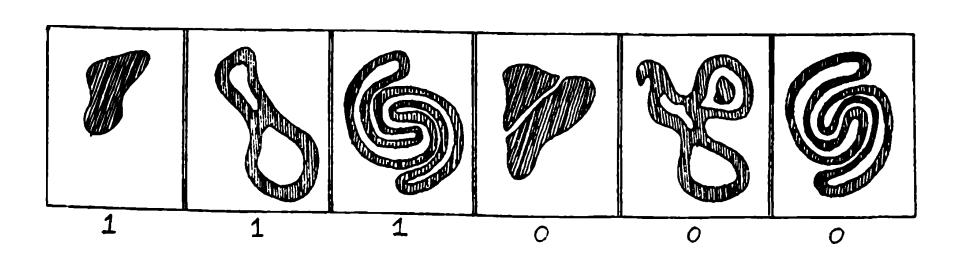
^CIRCl.l(^) — 1 if the figure A" is a circle, 0 if the figure is not a circle;
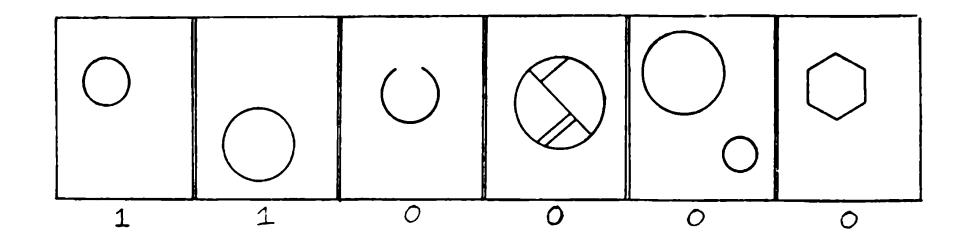
/ *(Y* J 1 if ^ is a convex figure, coNVbx ) |o if A'is not a convex figure;
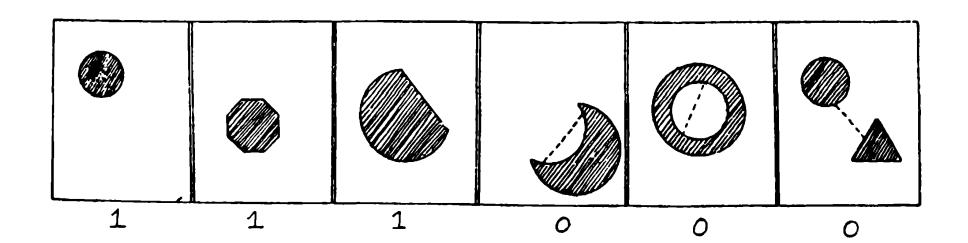
CONNbCTbl) (^) = 1 if A' is a connected figure, 0 otherwise.
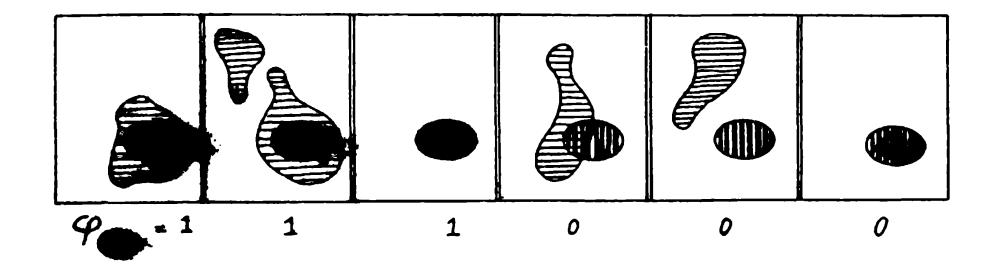
We will also use some very much simpler predicates.* The very simplest predicate " recognizes" when a particular single point is in X: let /7 be a point in the plane and define
$$\varphi_p(X) = \begin{cases} 1 & \text{if } p \text{ is in } X, \ 0 & \text{otherwise.} \end{cases}$$
Finally we will need the kind of predicate that tells when a particular set /i is a subset of *X*
$$\varphi_A(X) = \begin{cases} 1 & \text{if } A \subset X, \ 0 & \text{otherwise.} \end{cases}$$
*Om%*r iiiii uwmnft of
We stort by observing an important difference between ^ connect ed and CONVEX- To bring it out we state a fact about convexity:
DetMlIaii: A set AT fails to be convex if and only if there exist three points such that q is in the line segment joining p and r, and
$$\begin{cases} p \text{ is in } X, \ q \text{ is not in } X, \ r \text{ is in } X. \end{cases}$$
Thus we can test for convexity by examining triplets of points. If all the triplets pass the test then X is convex; if any triplet fails (that is, meets all conditions above) then X is not convex. Because all the tests can be done independently, and the final decision made by such a logically simple procedure—unanimity of all the tests—we propose this as a first draft of our definition of "local."
♦We will use 'V " instead of 'V " for those very simple predicates that will be combined later to make more complicated predicates. No absolute logical distinction is implied.
Definition: A predicate yp is conjunctively local of order k if it can be computed, as in §0.4, by a set 4> of predicates such that
Each $$\varphi$$ depends upon no more than $k$ points of $R$ : $$\psi(X) = \begin{cases} 1 & \text{if } \varphi(X) = 1 \text{ for every } \varphi \text{ in } \Phi, \ 0 & \text{otherwise.} \end{cases}$$
Example: \ivoNVEx conjunctively local of order 3.
The property of a figure being connected might not seem at first to be very different in kind from the property of being convex. Yet we can show that:
Theorem 0.6.1: connect ed not conjunctively local of any order.
pr o o f : Suppose that connect ed has order k. Then to distinguish between -the two figuros —

suck +U.-V %(Xo) becaose
there must be some wh4ch4»iri vnhrin 0 is not connected. All ** have value 1 on Yi, which is connected. Now, can depend on at most k points, so there must be at least one middle square, say 5^, that does not contain one of these points. But then, on the figure Y2,
which is connected, vj^must have the same value, 0, that it has on Yo. But this cannot be, for all v?'s must have value 1 on X>.
Of course, if some is allowed to look at all the points of R then ^CONNECTED can be computed, but this would go against any concept of the (^'s as "local'' functions.
0.7 Some Other Concepts of Local
We have accumulated some evidence in favor of "conjunctively local" as a geometrical and computationally meaningful property of predicates. But a closer look raises doubts about whether it is broad enough to lead to a rich enough theory.
Readers acquainted with the mathematical methods of topology will have observed that "conjunctively local" is similar to the notion of " local property" in topology. However, if we were to pursue the analogy, we would restrict the <^'s to depend upon all the points inside small circles rather than upon fixed numbers of points. Accordingly, we will follow two parallel paths. One is based on restrictions on numbers o f points and in this case we shall talk of predicates of limited order. The other is based on restrictions of distances between the points, and here we shall talk of diameter-limited predicates. Despite the analogy with other important situations, the concept of local based on diameter limitations seems to be less interesting in our theory—although one might have expected quite the opposite.
More serious doubts arise from the narrowness of the "conjunctive" or "unanimity" requirement. As a next step toward extending our concept of locals let us now try to separate essential from arbitrary features of the definition of conjunctive localness. The intention of the definition was to divide the computation of a predicate xp into two stages:
Stage I:
The computation of many properties or features ip a which are each easy to compute, either because each depends only on a small part of the whole input space R, or because they are very simple in some other interesting way.
Stage II:
A decision algorithm Q that defines by combining the results of the Stage I computations. For the division into two stages to be meaningful, this decision function must also be distinctively homogeneous, or easy to program, or easy to compute.
The particular way this intention was realized in our example ^CONVEX was rather arbitrary. In Stage I we made sure that the ipaS were easy to compute by requiring each to depend only upon a few points of R. In Stage II we used just about the simplest imaginable decision rule; if the (p's are unaminous we accept the figure; we reject it if even a single (p disagrees.
We would prefer to be able to present a perfectly precise definition of our intuitive local-vs.-global concept. One trouble is that phrases like "easy-to-compute" keep recurring in our attempt to formulate it. To make this precise would require some scheme for comparing the complexity of different computation procedures. Until we find an intuitively satisfactory scheme for this, and it doesn't seem to be around the corner, the requirements of both Stage 1 and Stage II will retain the heuristic character that makes formal definition difficult.
From this point on, we will concentrate our attention on a particular scheme for Stage II—"weighted voting," or "linear combination" of the predicates of Stage I. This is the so-called perceptron scheme, and we proceed next to give our final definition.
0.8 Perceptrons
Let4> = (pu (p2*, ... , (Pn]ht2i* family of predicates. We will say that
\l/ is linear with respect to 4>
if there exists a number 6 and a set of numbers |a^,, ..., a^J such that \p{X) = 1 if and only if (P{X) + • • • -f a^^(p"{X) > 6. The number 0 is called the threshold and the a s are called the coefficients or weights. (See Figure 0.2). We usually write more compactly
$$\psi(X) = 1$$ if and only if $\sum_{\varphi \in \Phi} \alpha_{\varphi} \varphi(X) > \theta$ .
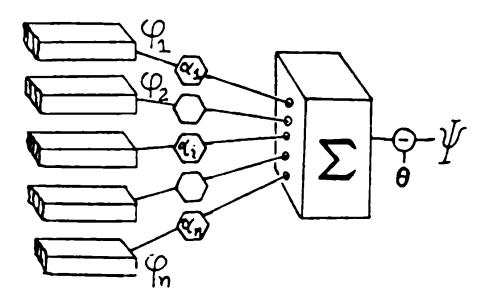
The intuitive idea is that each predicate of is supposed to provide some evidence about whether ^ is true for any figure X, If» on the whole, ^(A') is strongly correlated with ip(X) one expects to be positive, while if the correlation is negative so would be a^. The idea of correlation should not be taken literally here, but only as a suggestive analogy.
Example: Any conjunctively local predicate can be expressed in this form by choosing ^ = - I and = - I for every ip. For then
$$\sum (-1) \varphi(X) > -1$$ Or one could write (See §1.2.1) $$\sum \varphi(X) = 0 \text{, or } \sum \varphi(X) < 1.$$
exactly when <p(X) = 0 for every <p in . (The senses of t rue and FALSE thus have to be reversed for the <^'s, but this isn't important.^l
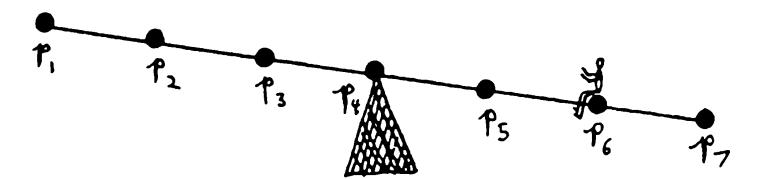
Example: Consider the seesaw of Figure 0.3 and let X be an arrangement of pebbles placed at some of the equally spaced points \P, •., Pi' Then R has seven points. Define ifi{X) = I if and only if X contains a pebble at the iih point. Then we can express the predicate
"The seesaw will tip to the right''
by the formula
$$\sum (i-4),\varphi_i(X)>0,$$
where ^ = Oanda, = (/-4 ).
There are a number of problems concerning the possibility of infinite sums and such matters when we apply this concept to recognizing patterns in the Euclidean plane. These issues are discussed extensively in the text, and we want here only to reassure the mathematician that the problem will be faced. Except when there is a good technical reason to use infinite sums (and this is sometimes the case) we will make the problem finite by two general methods. One is to treat the retina R as made up of discrete little squares (instead of points) and treat as equivalent figures that intersect the same squares. The other is to consider only bounded A''s and choose so that for any bounded X only a finite number of will be nonzero.
Definition: A perceptron is a device capable of computing all predicates which are linear in some given set of partial predicates.
That is, we are given a set of (^'s, but can select freely their "weights,'' the a^'s, and also the threshold For reasons that will become clear as we proceed, there is little to say about all perceptrons in general. But, by imposing certain conditions and restrictions we will find much to say about certain particularly interesting/aw/7/>.y of perceptrons. Among these families are
- Diameter-limited perceptrons: for each (p in the set of points upon which (p depends is restricted not to exceed a certain fixed diameter in the plane.
- Order-restricted perceptrons: we say that a perceptron has order < /7 if no member of depends on more than n points.
- Gamba perceptrons: each member of ^ may depend on all the points but must be a "linear threshold function'' (that is, each member of ^ is itself computed by a perceptron of order 1, as defined in 2 above).
- Random perceptrons: These are the form most extensively studied by Rosenblatt's group: the <^'s are random Boolean functions. That is to say, they are order-restricted and is generated by a stochastic process according to an assigned distribution function.
- Bounded perceptrons: contains an infinite number of v?'s, but all the lie in a finite set of numbers.
ijTo give a preview of the kind of results we will obtain, we present here a simple example of a theorem about diameter-restricted perceptrons.
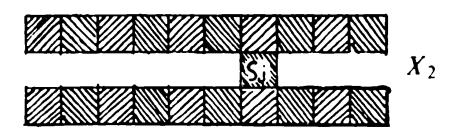
Theorem 0.8: No diameter-limited perceptron can determine whether or not all the parts of any geometric figure are connected to one another! That is, no such perceptron computes ^coNSECTtD-
The proof requires us to consider just four figures

and a diameter-limited perceptron \p whose support sets have diameters like those indicated by the circles below:
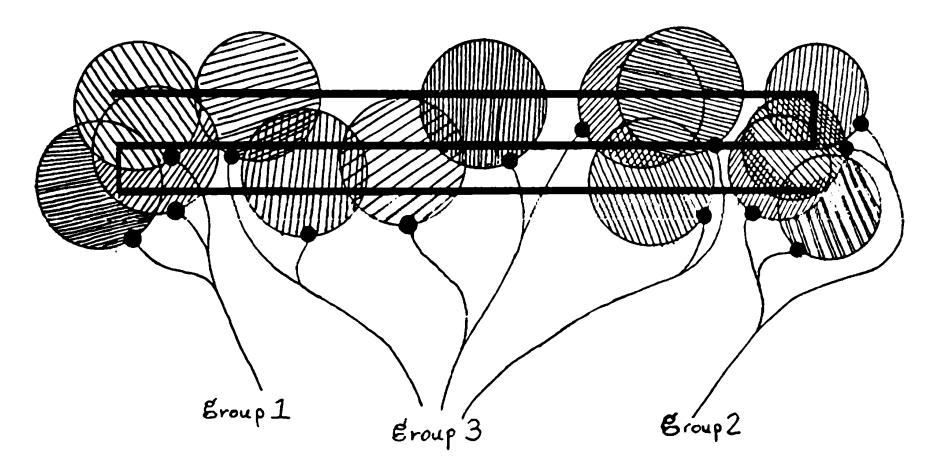
It is understood that the diameter in question is given at the start, and we then choose the Xijs to be several diameters in length. Suppose that such a perceptron could distinguish disconnected figures (like A'oo and A"n) from connected figures (like X and A'oi), according to whether or not
$$\sum \alpha_{\varphi} \varphi > \theta$$
that is, according to whether or not
$$\left[\sum_{\text{group 1}} \alpha_{\varphi} \varphi(X) + \sum_{\text{group 2}} \alpha_{\varphi} \varphi(X) + \sum_{\text{group 3}} \alpha_{\varphi} \varphi(X) - \theta\right] > 0$$
where we have grouped the v?'s according to whether their support sets lie near the left, right, or neither end of the figures. Then for Xoo the total sum must be negative. In changing Xoo to Xxo only 2 group I is affected, and its value must increase enough to make the
total sum become positive. If we were instead to change A"oo to A'oi then 2group2 would have to increase. But if we were to change A'oo to Xu, both 2group I and 2)group 2 will have to increase by these same amounts since (locally!) the same changes are seen by the group I and group 2 predicates, while 2group 3 is unchanged in every case. Hence, net change in the Xqo X u case must be even more positive, so that if the perceptron is to make the correct decision for Xqo, Xqi, and Xio, it is forced to accept Xu as connected, and this is an error! So no such perceptron can exist.
Readers already familiar with perceptrons will note that this proof which shows that diameter-limited perceptrons cannot recognize connectedness— is concerned neither with " learning" nor with probability theory (or even with the geometry of hyperplanes in n-dimensional hyperspace). It is entirely a matter of relating the geometry of the patterns to the algebra of weighted predicates. Readers concerned with physiology will note that—insofar as the presently identified functions of receptor cells are all diameter-limited—this suggests that an animal will require more than neurosynaptic "summation" effects to make these cells compute connectedness. Indeed, only the most advanced animals can apprehend this complicated visual concept. In Chapter 5 this theorem is shown to extend also to order-limited perceptrons.
0.9 Seductive Aspects of Perceptrons
The purest vision of the perceptron as a pattern-recognizing device is the following:
The machine is built with a fixed set of computing elements for the partial functions if, usually obtained by a random process. To make it recognize a particular pattern (set of input figures) one merely has to set the coefficients to suitable values. Thus "programming" takes on a pleasingly homogeneous form. Moreover since "programs" are representable as points (« 1**, «** 2**» • • •»** ci") in an Ai-dimensional space, they inherit a metric which makes it easy to imagine a kind of automatic programming which people have been tempted to call learning: by attaching feedback devices to the parameter controls they propose to "program" the machine by providing it with a sequence of input patterns and an "error signal" which will cause the coefficients to change in the right direction when the machine makes an inappropriate decision. The perceptron convergence theorems (sQt Chapter 11) define conditions under which this procedure is guaranteed to find, eventually, a correct set of values.
0.9.1 Homogeneous Programming and Learning
To separate reality from wishful thinking, we begin by making a number of observations. Let be the set of partial predicates of a perceptron and L(4>) the set of all predicates linear in 4>. Thus
- L(4>) is the repertoire of the perceptron—the set of predicates it can compute when its coefficients and threshold 0 range over all possible values. Of course L(^) could in principle be the set of all predicates but this is impossible in practice, since 4> would have to be astronomically large. So any physically real perceptron has a limited repertoire. The ease and uniformity of programming have been bought at a cost! We contend that the traditional investigations of perceptrons did not realistically measure this cost. In particular they neglect the following crucial points:
- The idea of thinking of classes of geometrical objects (or programs that define or recognize them) as classes of /i-dimensional vectors (of|, ... , a") loses the geometric individuality of the patterns and leads only to a theory that can do little more than count the number of predicates in *L(^)* This kind of imagery has become traditional among those who think about pattern recognition along lines suggested by classical statistical theories. As a result not many people seem to have observed or suspected that there might be particular meaningful and intuitively simple predicates that belong to no practically realizable set L(^). We will extend our analysis of ^ connect ed to show how deep this problem can be. At the same time we will show that certain predicates which might intuitively seem to be difficult for these devices can, in fact, be recognized by low-order perceptrons: ^ convex already illustrates this possibility.
- Little attention has been paid to the size, or more precisely, the information content, of the parameters «i, ..., a". We will give examples (which we believe are typical rather than exceptional) where the ratio of the largest to the smallest of the coefficients is meaninglessly big. Under such conditions it is of no (practical) avail that a predicate be in L(^). In some cases the information capacity needed to store «i, ... , a« is even greater than that needed to store the whole class of figures defined by the pattern!
- Closely related to the previous point is the problem of time of convergence in a "learning" process. Practical perceptrons are essentially finite-state devices (as shown in Chapter 11). It is therefore vacuous to cite a "perceptron convergence theorem" as assurance that a learning process will eventually find a correct
setting of its parameters (if one exists). For it could do so trivially by cycling through all its states, that is, by trying all coefficient assignments. The significant question is how fast the perceptron learns relative to the time taken by a completely random procedure, or a completely exhaustive procedure. It will be seen that there are situations of some geometric interest for which the convergence time can be shown to increase even faster than exponentially with the size of the set R.
Perceptron theorists are not alone in neglecting these precautions. A perusal of any typical collection of papers on "self-organizing" systems will provide a generous sample of discussions of "learning" or "adaptive" machines that lack even the degree of rigor and formal definition to be found in the literature on perceptrons. The proponents of these schemes seldom provide any analysis of the range of behavior which can be learned nor do they show much awareness of the price usually paid to make some kinds of learning easy: they unwittingly restrict the device's total range of behavior with hidden assumptions about the environment in which it is to operate.
These critical remarks must not be read as suggestions that we are opposed to making machines that can "learn." Exactly the contrary! But we do believe that significant learning at a significant rate presupposes some significant prior structure. Simple learning schemes based on adjusting coefficients can indeed be practical and valuable when the partial functions are reasonably matched to the task, as they are in Samuel's checker player. A perceptron whose $\varphi$ 's are properly designed for a discrimination known to be of suitably low order will have a good chance to improve its performance adaptively. Our purpose is to explain why there is little chance of much good coming from giving a high-order problem to a quasi-universal perceptron whose partial functions have not been chosen with any particular task in mind.
It may be argued that people are universal learning machines and so a counterexample to this thesis. But our brains are sufficiently structured to be programmable in a much more general sense than the perceptron and our culture is sufficiently structured to provide, if not actual program, at least a rather complex set of interactions that govern the course of whatever the process of self-programming may be. Moreover, it takes time for us to become universal learners: the sequence of transitions from infancy to intellectual maturity seems rather a confirmation of the
thesis that the rate of acquisition of new cognitive structure (that is, learning) is a sensitive function of the level of existing cognitive structure.
0.9.2 Parallel Computation
The perceptron was conceived as a parallel-operation device in the physical sense that the partial predicates are computed simultaneously. (From a formal point of view the important aspect is that they are computed independently of one another.) The price paid for this is that all the $\varphi_i$ must be computed, although only a minute fraction of them may in fact be relevant to any particular final decision. The total amount of computation may become vastly greater than that which would have to be carried out in a well planned sequential process (using the same $\varphi$ 's) whose decisions about what next to compute are conditional on the outcome of earlier computation. Thus the choice between parallel and serial methods in any particular situation must be based on balancing the increased value of reducing the (total elapsed) time against the cost of the additional computation involved.
Even low-order predicates may require large amounts of wasteful computation of information which would be irrelevant to a serial process. This cost may sometimes remain within physically realizable bounds, especially if a large tolerance (or "blur") is acceptable. High-order predicates usually create a completely different situation. An instructive example is provided by $\psi_{\text{CONNECTED}}$ . As shown in Chapter 5, any perceptron for this predicate on a 100 × 100 toroidal retina needs partial functions that each look at many hundreds of points! In this case the concept of "local" function is almost irrelevant: the partial functions are themselves global. Moreover, the fantastic number of possible partial functions with such large supports sheds gloom on any hope that a modestly sized, randomly generated set of them would be sufficiently dense to span the appropriate space of functions. To make this point sharper we shall show that for certain predicates and classes of partial functions, the number of partial functions that have to be used (to say nothing of the size of their coefficients) would exceed physically realizable limits.
The conclusion to be drawn is that the appraisal of any particular scheme of parallel computation cannot be undertaken rationally without tools to determine the extent to which the problems to be solved can be analyzed into local and global components. The lack of a general theory of what is global and what is local is no excuse for avoiding the problem in particular cases. This study will show that it is not impossibly difficult to develop such a theory for a limited but important class of problems.
0.9.3 The Use of Simple Analogue Devices
Part of the attraction of the perceptron lies in the possibility of using very simple physical devices—"analogue computers"—to evaluate the linear threshold functions. It is perhaps generally appreciated that the utility of this scheme is limited by the sparseness of linear threshold functions in the set of all logical functions. However, almost no attention has been paid to the possibility that the set of linear functions which are practically realizable may be rarer still. To illustrate this problem we shall compute (in Chapter 10) the range and sizes of the coefficients in the linear representations of certain predicates. It will be seen that certain ratios can increase faster than exponentially with the number of distinguishable points in R. It follows that for "big" input sets say, /?'s with more than 2 0 points—no simple analogue storage device can be made with enough information capacity to store the whole range of coefficients!
To avoid misunderstanding perhaps we should repeat the qualifications we made in connection with our critique of the perceptron as a model for "learning devices." We have no doubt that analogue devices of this sort have a role to play in pattern recognition. But we do not see that any good can come of experiments which pay no attention to limiting factors that will assert themselves as soon as the small model is scaled up to a usable size,
0.9.4 Models for Brain Function and Gestalt Psychology
The popularity of the perceptron as a model for an intelligent, general-purpose learning machine has* roots, we think, in an image of the brain itself as a rather loosely organized, randomly interconnected network of relatively simple devices. This impression in turn derives in part from our first impressions of the bewildering structures seen in the microscopic anatomy of the brain (and probably also derives from our still-chaotic ideas about psychological mechanisms).
In any case the image is that of a network of relatively simple elements, randomly connected to one another, with provision for making adjustments of the ease with which signals can go across the connections. When the machine does something bad, we will "teach" it not to do it again by weakening the connections that were involved; perhaps we will do the opposite to reward it when it does something we like.
The "perceptron" type of machine is one particularly simple version of this broader concept; several others have also been studied in experiments.
The mystique surrounding such machines is based in part on the idea that when such a machine learns the information stored is not localized in any particular spot but is, instead, "distributed throughout" the structure of the machine's network. It was a great disappointment, in the first half of the twentieth century, that experiments did not support nineteenth century concepts of the localization of memories (or most other "faculties") in highly local brain areas. Whatever the precise interpretation of those not particularly conclusive experiments should be, there is no question but that they did lead to a search for nonlocal machinefunction concepts. This search was not notably successful. Several schemes were proposed, based upon large-scale fields, or upon "interference patterns" in global oscillatory waves, but these never led to plausible theories. (Toward the end of that era a more intricate and substantially less global concept of "cell-assembly" —proposed by D. O. Hebb [1949]—lent itself to more productive theorizing; though it has not yet led to any conclusive model, its popularity is today very much on the increase.) However, it is not our goal here to evaluate these theories, but only to sketch a picture of the intellectual stage that was set for the perceptron concept. In this setting, Rosenblatt's [1958] schemes quickly took root, and soon there were perhaps as many as a hundred groups, large and small, experimenting with the model either as a "learning machine" or in the guise of "adaptive" or "self-organizing" networks or "automatic control" systems.
The results of these hundreds of projects and experiments were generally disappointing, and the explanations inconclusive. The machines usually work quite well on very simple problems but deteriorate very rapidly as the tasks assigned to them get harder. The situation isn't usually improved much by increasing the size and running time of the system. It was our suspicion that even in those instances where some success was apparent, it was usually due more to some relatively small part of the network, and not really to a global, distributed activity. Both of the present authors (first independently and later together) became involved with a somewhat therapeutic compulsion: to dispel what we feared to be
the first shadows of a "holistic" or "Gestalt" misconception that would threaten to haunt the fields of engineering and artificial intelligence as it had earlier haunted biology and psychology. For this, and for a variety of more practical and theoretical goals, we set out to find something about the range and limitations of perceptrons.
It was only later, as the theory developed, that we realized that understanding this kind of machine was important whether or not the system has practical applications in particular situations! For the same kinds of problems were becoming serious obstacles to the progress of computer science itself. As we have already remarked, we do not know enough about what makes some algorithmic procedures "essentially" serial, and to what extent—or rather, at what cost—can computations be speeded up by using multiple, overlapping computations on larger more active memories.
0.10 General Plan of the Book
The theory divides naturally into three parts. In Part I we explore some very general properties of linear predicate families. The theorems in Part I apply usually to all perceptrons, independently of the kinds of patterns considered; therefore the theory has the quality of algebra rather than geometry. In Part II we look more narrowly at interesting geometric patterns, and get sharper but, of course, less general, theorems about the geometric abilities of our machines. In Part III we examine a variety of questions centered around the potentialities of perceptrons as practical devices for pattern recognition and learning. The final chapter traces some of the history of these ideas and proposes some plausible directions for further exploration.
To read this book, one does not have to "know" all the mathematics mentioned in it. Most of the "harder" mathematical sections are "terminal"—they can be skipped without losing the sense of later chapters. The best chapters to skip are §4, §5, §7, and §10.